
From Technical Debt to Technical Health with HealthCheck
Why software fails and how you can practically address it with a 6-step plan.
It is common that software-producing teams struggle with their business counterparts when it comes to technical debt. If you’ve ever built a software system or product, and have been hampered by how hard it is to evolve it at the expected rate, and subsequently tried to argue for allocating time for accrued technical debt, then you might have heard one or more of these at some point:
- 🤔 “Why didn’t you build it right the first time?”
- 🧠 “I don’t think you need that.”
- 🤗 “I don’t have those issues!”
- 😂 “You’re just taking the piss, aren’t you?”
- 😰 “We don’t have time nor money for nice-to-haves right now…”
- 😡 “Is this actually a problem or are you just gold-plating the damn thing?”
- 👺 “So now you want more money to do what you failed to do the first time around!?”
- 🙈 “Christ almighty, don’t go telling Management about this!”
Let’s be clear: Unless you own the budget, you’ll never have absolute leverage in this (or any) situation. And, unfortunately, there will not come an opportunity in which there is suddenly time and money to do these activities—you’ll probably get the hint already in the intonation and delivery of the statement from your counterpart! How on Earth do we align on the necessity of addressing the technical debt that is damaging our team and product?!
In this article, I’ll propose a way to understand technical debt and how we can make it a concrete, meaningful notion for all involved parties—one that is possible to quantify, qualify, and solve. We’ll round off with a 6-step strategy to tackle technical debt, including running a HealthCheck review and offering a way to calculate your technical debt.
After reading, I hope those of you in the “business” track can better understand the nature and pedigree of technical debt and consider why it’s wise to repay it, and that those of you closer to the technology will be able to quantify risks and costs involved with unrestrained technical debt.
Why software fails
There are few, if any, really good reasons why software fails purely because of technical reasons.
How about we look at some common issues that undermine software? A very selective and incomplete set of conditions follows below (add or substitute “lack” with “poor” as needed):
- (Artificial) urgency drives unconsidered, poor decision-making.
- Lack of clarity and good requirements drives incorrect implementation and missing deadlines.
- Lack of efficiency drives waste such as handoffs, delays, and defects.
- Lack of communication drives misunderstandings, incorrect implementation, frustration, and undermines well-being.
- Lack of strategy forces an uncertain, potentially wrong, and overly broad solution space.
- Lack of organizational understanding of the nature of software drives “feature factory” behavior, poor quality, and legal/security/customer risk.
- Lack of ownership of the software drives disengagement and apathy, attrition, possible delays, and additional costs for replacing staff.
- Lack of competence drives poor implementation, bugs, overblown budgets, increased risks (legal, security, customer), and missed deadlines.
In traditional, non-technology organizations, the primary reason for failing software projects/products seems to me to be the misalignment of expectations between business and engineering counterparts. The key missing piece seems to be how non-functional qualities—an integral part of good engineering and software architecture—are sidestepped in many products/projects. The problem is that if you are not spending any meaningful time on these (i.e. resiliency, scalability, maintainability, security…) then virtually you have no more than a husk of software—yet, many are content with this. Problematically, the bar of expectations is set, on the “business end”, by how all other software behaves: Software with names like Facebook, Google, and Netflix; software that doesn’t just “magically work”. The effort to make them work well is high, and the cost is similarly high. But all of that is completely invisible to the naked eye.
This situation is further worsened by the overall lack in software engineering of objective, measurable compliance objects in the engineering output, often leading to over-confident Product Owners delivering what is effectively junk (though on time!) that does not hold water when non-functional details are reviewed, verified to be missing, but implicitly expected from the sponsors. We see this a lot, “optimizing for output over outcome”. Don’t do this, do the opposite! Outcomes are important, outputs aren’t—unless they lead to the desired outcomes.
In a poor-functioning software-developing organization, the first casualties of software are the non-functional qualities, soon leading to the technical deficiencies we often think of when we talk about technical debt.
What is technical debt?
The most common definition goes back to Ward Cunningham’s analogy of technical debt being like financial debt:
Shipping first time code is like going into debt. A little debt speeds development so long as it is paid back promptly with a rewrite… The danger occurs when the debt is not repaid. Every minute spent on not-quite-right code counts as interest on that debt.
— Ward Cunningham (1992)
This is still a pretty good general concept! However, to be more precise and to get rid of the analogy of financial debt, a more recent definition that I’d recommend instead is:
In software-intensive systems, technical debt consists of design or implementation constructs that are expedient in the short term but that set up a technical context that can make a future change more costly or impossible. Technical debt is a contingent liability whose impact is limited to internal system qualities — primarily, but not only, maintainability and evolvability.
— Philippe Kruchten, Robert Nord & Ipek Ozkaya: Managing Technical Debt: Reducing Friction in Software Development (2019), p. 5.
Here we get the clear sense that true technical debt is intentionally chosen and that it does not, as such, have anything to do the software working or not—that is expected; if it’s not working then it’s defect, plain and simple, rather than being a matter of technical debt, though clearly technical debt can drive the production of defects as an effect. It’s contingent as there may, or may not, come a future situation in which the debt needs to be paid.
Note also how intentional technical debt differs in many ways from unintentional debt:
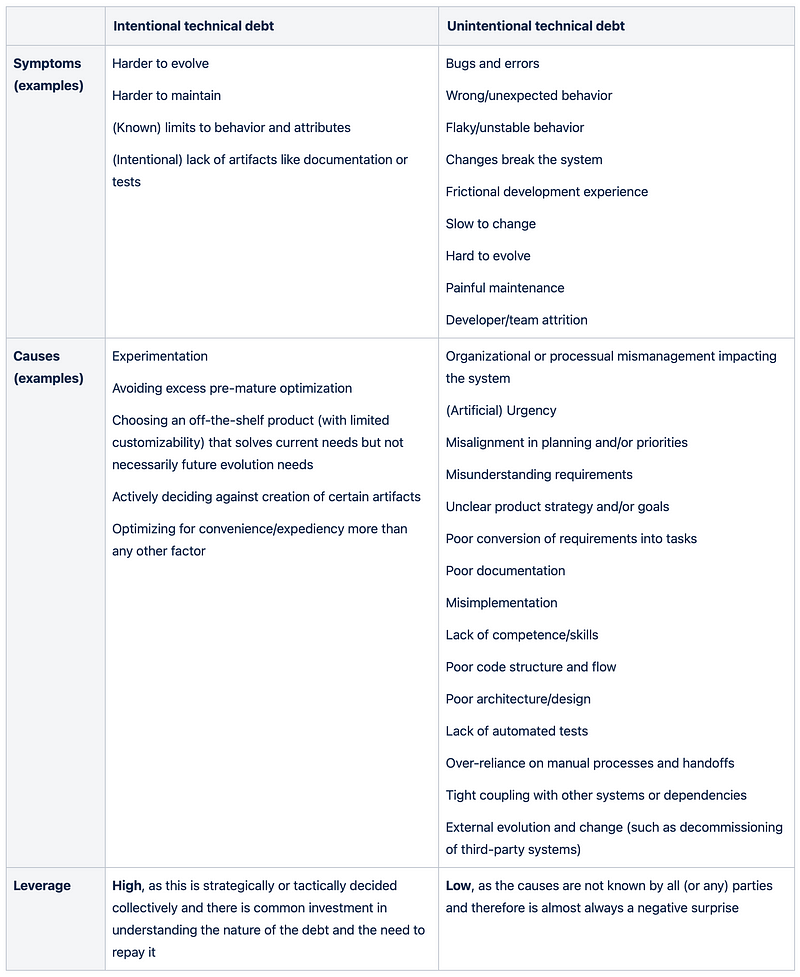
We will look deeper at this distinction in a bit.
Some reject technical debt and dismiss it as a theoretical problem. In fact, perhaps the two deadliest sins of misunderstanding technical debt are variants of:
- 😱 Technical debt can be avoided.
- 👻 Technical debt has no actual price.
Unfortunately, both notions are patently untrue.
We could even, like Eric Higgins aptly writes, simply accept that technical debt is like Tetris:
“You can’t win. You can only control how quickly you lose.”
Software isn’t magic, but it’s very different from matter in the physical world
A big reason for why these statements are wrong is that software is a dynamic, moving matter; as an entirety, it’s not static or predictable.
The complexity of software is an essential property, not an accidental one. Hence descriptions of a software entity that abstract away its complexity often abstract away its essence. […] Many of the classical problems of developing software products derive from this essential complexity and its nonlinear increases with size. From the complexity comes the difficulty of communication among team members, which leads to product flaws, cost overruns, schedule delays. […] Not only technical problems but management problems as well come from the complexity.
— Frederick P. Brooks Jr., “No Silver Bullet” (1986)
Good software engineering and software architecture aims to regulate and control the illusive essence of software so that it can be safely and easily maintained and evolved. Good code is, as I’ve written before, deterministic and “dumb” (among other things). Writing good code is hard, and it’s a trade that has a lot to do with understanding how to build, evolve, and operate (sometimes incredibly complicated) systems.
The essence of software is that it’s naturally complex and that it also tends to have to evolve co-dependently with a changing world (with all of its expectations) and a changing set of requirements forming the precise scope of the system. Thus, software isn’t static, and one way a software engineer works with the solution is to make it supple: In terms of metaphors, think of a piece of wood that you want to drive a screw into. If you drive it in too hard, the wood splits; do it too softly and the screw doesn’t even enter. Similarly, engineers and architects are careful to balance their abstractions, models, and patterns (etc.) to attain such a balance. Complexity increases logarithmically—at least it feels so—when a system grows more intricate. That’s why key skills of a high-performing team include relentlessly controlling the codebase, the delivery, and the processes involved to ensure a lean, efficient, productive, and healthy flow. Losing that control means allowing “more dust into the cleanroom” spoiling the work, and risking the overall flow to descend into chaos.
As architects and engineers, we continuously make decisions that try to support the requirements, for example, by balancing the composition of abstractions (to support clearer evolution) with the right amount of “unoptimized” implementation to save on direct effort (and because we might not need the abstractions in the long run). Here, it’s evident that technical debt cannot be avoided: It will come either unintentionally — as an effect, sometimes, of misguided implementation — or intentionally, when we (as a team) decide on a less modular system design to save time today, deferring this for extra evolution time in a future that is contingent, that is, it may or may not come. If not all parties are aware of this—and to be frank, to this day most people in “business” don’t care that much about software—to non-technical staff, the negative surprise of technical debt at a later point will be harrowing and strange.
Don’t underestimate the significant difference between the debt you take — which you know, control, can repay in an ordered fashion, and negotiate about with all parties — and that which is naturally added on top by working, evolving, and updating a codebase over time, sometimes not in a very good way. The debt comes, inevitably, by simply working. With good thinking, technical skills, and a healthy team we can keep the debt at a low in-going rate, but the less we have of our success factors (skills, health…), the higher the risk and rate of an uncontrolled spiral into unintentional debt.
This is where traditional organizations once and for all show their issues with (not) delivering good software made by high-performing teams.
Entropy, code rot, and debt in organizations
Sorry, but I need to make things even worse now. The above is just for your code. However, dependencies being updated outside of your codebase aren’t (in many cases) deterministic. And there might be other external negative stimuli such as power failures on a server, electrical issues on a chip, or an outage in a cloud service that you connect to. Not to speak of all of the possible and impossible behaviors people will start subjecting the system to! It’s clearly impossible to defend every angle at every level, from user to usage to chip to networking to the software itself.
Further, continuing on what Fred Brooks noted already in the 1980s,
- the more complex something is…
- the less well-understood the system is…
- the less nimble the organization and its communication patterns around it is…
- and the bigger the organization itself is,
the more we’ll end up with people problems rather than tech problems because of the explosion in communicative complexity. This is close to what is nowadays known as Brooks’ Law, or as he wrote in The Mythical Man-Month:
“Adding manpower to a late software project makes it later”.
To make matters worse, people problems tend to inevitably lead to tech problems, because if we don’t know what we are making (in truth: how we are evolving the system), and how it may be done in a competent manner, the more technical debt we will end up with. Because of the nature of our issues, chances are the debt will be unintentional in nature, which is generally worse than intentional debt (which we know; balance; choose; control).
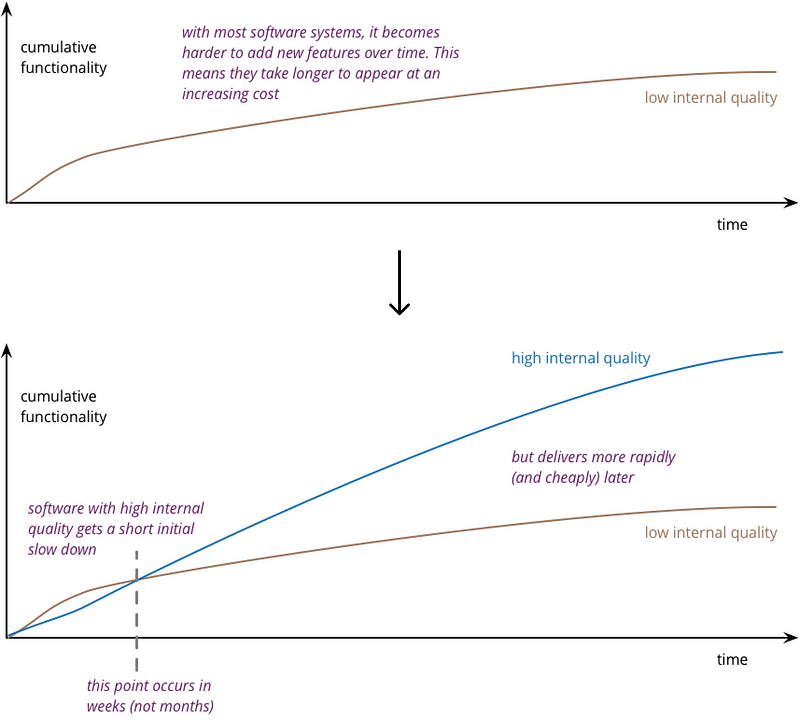
Can’t we just set up more control structures? Yes and no. As Martin Fowler has written, and most of us techies have experienced, high quality (unlike in most other industries) has an inverse relation to speed: It’s actually the case that higher quality software is faster to work with. That’s also one of the core premises of the well-renowned and well-established DORA metrics, where deployment frequency and lead time to change are two indicators of high-performing software teams. So, no, the answer isn’t more people and processes, but rather more automation and technical guardrails. Beware that the level of these controls still won’t catch bad decisions, rushed solutions, or dumb ideas! Those are, yet again, people problems that can only be correctly alleviated by arranging the organization and processes in a way that makes sense and does not create these situations.
For those of you following me on a more regular basis, you’ll know I (blasphemously) think that a lot of organizations — every single one I’ve ever worked with, in fact — lack truly foundational skills to deliver high-quality software, and that many engineers fail to grasp modern concepts, making lots of products/projects cling to assumptions of how things were supposed to be handled, rather than how we can effectively solve those same problems today. So if you are in this bucket, don’t feel bad! But change can only happen with effort and will: You cannot force competence—only select for it and create the conditions to develop it. With the dramatic changes in technology in the last decade, incompetence has become an even bigger driver of unintentional technical debt. But it’s not nearly the only one; we need to look not only at the individual engineer, but to the whole organization they are in.
Part of the solution to this organizational problem should include tighter, vertical, lean products where all stakeholders collaborate on a more regular and transparent basis — a good option is agile. While there are numerous “schools of agile”, the principles and practices are much more important than choosing a supposedly “ready-to-use” framework, such as Scrum or SAFe. I can recommend Jonathan Smart’s Sooner Safer Happier and this DORA article as good entrypoints if you want to rethink your organization in such terms.
What can we conclude so far?
- Larger groups have higher degrees of communication burden.
- Adding 1X additional headcount does not give you 1X additional output; rather it gives you roughly 0.5–0.7X more output.
- Technical debt, when it becomes unkempt and starts compounding interest, will drag your system/product and team down with it. And make no mistake: It’s a lot of time! According to Stripe, it’s 31.6% of a developer’s time; Raygun claims it’s about 20%; Codescene writes it’s in the range of 23- 42%; and lastly, work I’ve done at Polestar supports these overall numbers so I think they are reasonable.
- Everything that harms the productive use of time, such as rampant technical debt, is a non-value-adding cost.
In total, there is just no way to make the entirety of software predictable and without technical debt, and therefore, without cost. Technical debt has very real costs. Consequently, the question isn’t “Why do I have to pay for technical debt?”, but rather “How do we attack the technical debt we are already paying for today so we can pay less for it in the future?”.
How do we start the journey to becoming a team that can handle technical debt in a thorough, progressive, fully aligned, and invested manner? And even more importantly:
How do we express the actual, real, evidenced problems of our current state, ideally in a way in which we can progressively attack those bad parts and grow stronger, with full support and commitment from all parties, including (for example) our business counterparts?
A battle plan to fight technical debt
A plan to tackle technical debt should address multiple angles:
- Define technical debt and make it a shared understanding. At Polestar Digital we use Kruchten, Nord, and Ozkaya’s book as part of our definition (refer to quote further up). Make sure all relevant parties know of this definition, or even take part in its inception, so that there is a common ground and a clear idea of why technical debt is a business problem if kept unchecked.
- Run a survey in your team(s), asking the software engineers how much they estimate they spend on the effects of technical debt today, i.e. bugs, additional maintenance, handoffs, lack of documentation, and so forth. For questions, you could get inspired by Stripe’s The Developer Coefficient, the SPACE framework or the DevEx framework and their example questions. Use any tool you have on hand, such as Microsoft Forms, Google Forms, Typeform, or even an online Excel file to conduct the survey.
- If possible, gather hard data too, for example from your version control system, CI/CD systems, and ticket systems, remembering that experience and actuals are two sides of the same coin. There are even engineering analytics tools like Swarmia, Hatica, and LinearB that are able to get such numbers more easily and even directly quantify performance data into costs.
- Quantify the cost of the current state, using even just a basic calculation. I made one available as a Google Sheet, which you can tweak as needed. It’s not rocket science, given the calculation is mostly about putting a number on the amount of non-business-value-adding work conducted. The most important part here is that you provide a realistic assessment of the time that is actually spent “living with debt” today.
- Add tooling such as static code analysis to catch, inform, prioritize, and help improve your codebase. This is a vast field that will depend on your tech stack, culture, and other factors. I’d recommend putting such tools in the pre-commit and CI stages, but there is also a communal and transparency-creating value in having specialized tools, external to the CI, to represent issues, trends, and actionable items to focus on. Some tools for this usecase include CodeScene, DeepSource, SonarCloud, and Embold.
- Run a problem-oriented technical debt review, such as the HealthCheck, to identify, quantify, prioritize, and assign debt items with clear resolution criteria to people who can take concrete actions to solve the issues.
As you see, there is no possibility to effectively remove all technical debt as only a technical activity by yourself (well, unless you actually do work alone).
Moving on: Let’s dig deeper into the HealthCheck approach!
Problem-oriented reviews instead of compliance checks
The traditional review model is additive: It methodically and precisely adds small pieces (compliance to X, Y, Z…) to a void where nothing exists prior to the review. Therefore it is fair to say that such a model is review-centric, and while exact in nature, it is also a less pragmatic approach. Since these tend to take more time and might be more focused on procedure and outputs, it won’t necessarily be a good instrument to understand the effect of missing parts. How can I determine the consequence of missing an expected activity?
When it comes to our own physical health, we are more inclined to explain the experienced problems than first expressing in minute detail everything that works fine, and only then at some later point finally arrive at the few things we sense as issues.
The real issue with debt as a concept is that, while it’s accurate in a transactional sense, it doesn’t encapsulate the actual symptoms and conditions of those building and delivering software. It’s more like a constant grind and burden, like being stuck in toffee, going slower every day, rather than an impassable wall that you suddenly encounter. Legendary software engineer Kent Beck wrote as much,
It’s not what you say, it’s what they hear. Many business folks hear “mistakes”, “delay”, and “no progress” when they hear “technical debt”.
We aren’t wrong in talking about “technical debt”. The structure really does need investment, either because our needs have outgrown our earlier decisions or our understanding has outgrown them. We need a metaphor more likely to encourage helpful behavior, like scope and priority decisions, and less likely to encourage damaging behavior, like shame and pressure.
I’ve begun using “friction” when talking to business folk. We want to reduce friction in development. I’m talking about the same activities, the same structural investments, as when I talked about “reducing technical debt”, but I’m using different language. What I like about the friction metaphor is it implies that we are continuing to move forward.
— Kent Beck, “Friction” >> “Debt”
I believe it is wise to take this friction as a strong signifier of technical debt — it’s concrete, often quantifiable, and clearly bad, but not immediately crippling.
We might call this “doctor’s appointment model” subtractive since we reduce something—the problem; such as the insistent cough, or the flaky tests—from the whole: our body or whatever else we find to be working essentially as it should in most aspects. This model fundamentally assumes that we care only about actual or likely issues; it is inherently less exact, but faster in terms of scoping out the problem space. Here we gain confidence in the flaws of certain of our existing outcomes. Thus, we already know for a fact that a “bad check” in the review is a real problem, and vice versa.
In other words, we make it clearer that adding friction (technical debt) means it becomes harder to achieve things we want — such as short value lead times, safe and functional experiences for the end-user, easy onboarding of developers, and delivering high-quality non-functional abilities.
The HealthCheck review
The HealthCheck review format is a quick, high-level review of your technical solution/system. It aims to flush out where there are meaningful implementation or design deficits in your solution. As such, it’s not a complete, detailed solution review.
The review is essentially a number of statements about the functionality and performance of your system that you answer by checking boxes, from most problematic to no problem existing, basically assessing if you are having certain pains or if you are missing certain important expected outputs. While these statements should generally apply to many types of software systems, feel free to modify and change a copy of the template to your own needs.
In total, a HealthCheck is meant to be to be run swiftly in about an hour, hence the tone and approach is not of scientific rigor but of good old teamwork and a Get Shit Done attitude. It’s even advisable to run this specific review every month, rather than doing it as a rigorous, ritual activity once per year. Remember that feedback is king when it comes to software development!
Credit where credit is due: The format, overall, is inspired by all the previously mentioned sources, as well as REA Group’s 3x3 canvas and Laura Tacho’s writings (such as this and this).
Instructions
Running the review should be quite simple. Fuller instructions can be seen in the template, but the overall steps are no more than:
- Review (~30 minutes): Gather your team. Read each statement aloud. Start from the left and tick all boxes that apply. If nothing applies, tick the box in the green column. If the statement itself doesn’t apply, just strike it and don’t tick anything. Make a basic trend analysis: Has it gotten better or worse? Mark it with an appropriate emoji, arrow, text, or color. Continue through all statements.
- Prioritization (~10 minutes): You’ll now have a fairly good quantitative understanding of your technical health (or debt) when looking at the values in the first (red) and second (yellow) columns. Discuss the accumulated points and decide on prioritized tasks. What areas seem most affected by debt? Mark prioritized tasks.
-
Debt tracking (~20 minutes): Answer the “what, why, when,
who”-style questions. Add each task to your ticket system under a dedicated label,
such as
techdebt.
In about an hour, you should have gone full circle and found some crisp priority action points to work on.
Quantifying the debt
Now it’s time to make a copy of the Technical Debt Cost Calculation Template and start calculating your monthly costs!
The template comes pre-populated with some leading numbers on yearly developer salaries (in the EU) and time spent on technical debt (using Stripe’s 31.6% average). You could try getting a more accurate average salary from your HR department, Glassdoor, levels.fyi, public records, a relevant union, or your national statistics agency. From your surveys, productivity data, and HealthCheck reviews you should have an estimate of your productivity loss incurred by technical debt (and perhaps other factors as well).
Using it is as simple as inputting your numbers!
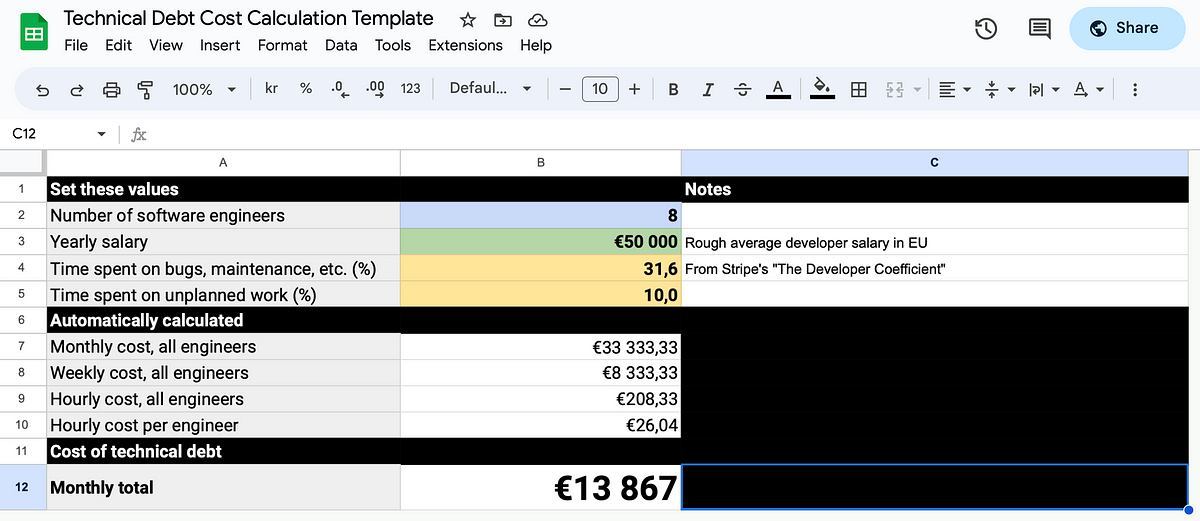
For these numbers, a viable option now is to start arguing that if you, for example, spend €2M per year on technical debt, would it be possible to realign the planning and/or budget to allocate some percentage (25%? 50%?) to actually deal with technical debt management rather than putting it on the feature budget (or similar, whatever makes sense in your organization) where it will literally go to waste?
To make it crystal clear: The numbers you’re seeing are what you are already paying for; it isn’t fresh money. Worse—it’s all a useless use of the money you’ve got. Put the money to good use instead!
End note: Nothing replaces doing the actual work
Technical debt is, as we’ve seen, a complicated subject which I hope that you now feel you are somewhat more in control of. We’ve now learned many things, such as:
- How technical debt is actually not as “cheap” or “invisible” as it’s sometimes made to seem—it’s both expensive and often very tangible for teams.
- How there are several very actionable things you, your team, and your organization can do to attack technical debt…and win!
- How a problem-oriented review simplifies the identification and quantification of technical debt, compared to compliance-oriented reviews.
Next, the key thing is to actually do the work and not just relegate technical debt inventory to a review that is quickly forgotten, or ask for next year’s budget to work on debt items that you can handle in your day-to-day work and which have concrete, negative implications today.
Nothing replaces doing the actual work. Good luck!