
Secrets Management in the Cloud
Solving the run-time vs compile-time conundrum.
A somewhat popular brain teaser of a software architecture question is:
“Where do I store my secrets?”
First things first: What is a secret? A secret is confidential and sensitive information that needs to be protected from unauthorized access or disclosure. Typical examples of this could include passwords, encryption keys, API tokens, and other data that, if exposed, could compromise security or privacy. You will have an awful time creating secure software if you aren’t using secrets. Moreover, we want to disambiguate a secret from a mere configuration value as they are often conflated—more on that in a bit.
Many software engineers will have read The Twelve-Factor App and its Config section. Unfortunately, for many of us working today and with tooling that didn’t exist back then, some of those recommendations have gone sour with time. When it comes to secrets management, this part of the 12-factor concept doesn’t quite hold up in all cases.
Let’s therefore pick the question apart and look at some better options.
Some notes before we start:
- While I don’t use a lot of Docker, there is a bit of reading to do concerning secrets management in that, too, which I won’t cover here.
- Over on LinkedIn, the option of using sealed-secrets was mentioned if you are in the Kubernetes space.
How to store the secret in the first place?
Let’s first figure out how to store the secret.
You really don’t want to check in secrets
There are so many stories around lax development practices leading to both small and huge data leaks because of developers making their secrets available to anyone with access to the source code.
A convention that exists among developers is using files, such as .env,
to store configuration values. Using .gitignore they’ll ensure Git
won’t pick up that data. But where do they get the values from initially?
- One option is that they store it in an insecure environment, like in their local notetaking app, in a shared documentation surface, or in direct messaging tools like Slack. For insensitive parameters this is fine.
- Another option is that they store them in a secure environment, such as a collectively accessible password manager, such as Bitwarden or 1Password. Using group-based and personal restrictions, you end up with a great way to store access tokens and other sensitive data.
Generally, we can establish that checking in stuff like
appsettings.json shouldn’t be an issue,
given the values contained therein are of a generic, insensitive nature; literally being application settings. Keep doing this, as per the Twelve Factor
advice!
Infrastructure-as-code as a (partial) solution
When managing cloud resources, use Infrastructure as Code (IAC) tools like Terraform, AWS CloudFormation, or Azure Resource Manager templates. The idea is to store secrets separately from your IAC code and use the respective secrets management tools to inject them into the application at runtime.
There’s a small catch-22 though. You’ll have to somehow originally assign the secret’s value to the infrastructural resource. I haven’t personally figured out a water-tight way to add the actual, real secret into cloud environments without doing this manually, in order to avoid the secret being stored in source code somewhere. I’m open for the possibility that such options exist, but I don’t see anything dramatically bad using, for example, a password manager such as Bitwarden, Proton Pass, or 1Password to contain these “origin” secrets. Thus: Create infrastructure for secrets with IAC but add the values to the resources manually. It’s not perfect, but it’s a clean way.
Breaking down the original question
Back to the starting question.
To solve it, we can use a few proxy questions to better understand the nature of our use case.
The first thing we have to do is understand the actual level of secrecy (I know, I tried other words!):
- Is the secret actually more of a configuration value or parameter? In this case it’s hardly a “secret”, is it? 😉
- Is the secret “kind-of-secret”, such as a commonly known value (shared tokens come to mind) in your organization? These shouldn’t leak, but it’s not the end of the world if they do, because you hopefully have a plan to rotate them quickly and painlessly.
- Is the secret owned by an individual user? In which case it’s highly secret and leakage would break the confidentiality (and trust) of your system.
The second aspect is understanding the level of uniqueness in the secret:
- Is the secret completely static and unchanging (at least over an extended period of time)?
- Is it the same secret being used deterministically across all cases, such as a secret that depends on the stage (i.e. DEV, QA, PROD)? In this case there is a bit of logical/structural coupling on the values.
- Is the secret pulled and used uniquely for a given actor, say a user? In this case we can’t know, or possibly even access, the secret before-hand.
The third question concerns context isolation:
- Is the value shared across multiple contexts (i.e. multiple applications)?
- Does the secret have to be validated at the time of an operation being performed or is it enough to have a precompiled response?
- How does secrets rotation impact systems? Is it contained to a single system or will multiple systems need to update?
Secrets don’t come in one size
Our question can now be rephrased into asking when the secret should be accessed:
- Do we need it at compile-time?
- Do we need it at run-time?
Compile-time
Compile-time secrets are configuration values that are known and set during the software development and build process. These secrets are typically stored securely (encrypted) and used to compile the code or build application artifacts.
An example of such usage is baking in secrets in GitHub, GitLab, Azure DevOps, or any other such tool. I’ll give two examples to contextualize.
An abbreviated example using a GitHub workflow could look like this:
name: main
[...]
jobs:
deploy:
uses: my_org/my_repo/.github/workflows/deploy.yml@main
secrets:
aws-role-arn: ${{ secrets.AWS_ROLE_ARN }}
This uses GitHub’s built-in secrets management where the value can only be read back by the CI workflow.
Another example, using Serverless Framework (version 3) to fetch a secret in AWS Secrets Manager:
service: my-service
[...]
custom:
config:
# In SLS, this needs to be set as a reference before we can get the actual value
SOME_CREDENTIALS: ${ssm:/aws/reference/secretsmanager/MyThingHere}
# Now that the reference is set, we can point to the field in the secret
someValue: ${self:custom.config.SOME_CREDENTIALS.SOME_VALUE}
During the compilation phase, Secrets Manager will be called and the value will be baked in according to your configuration. Ergo, if the person/machine calling the compilation is not permitted to access Secrets Manager and the specific secret, then it’s going to fail.
These secrets are ultimately made available via environment variables. This is nice and all, but it’s not necessarily very secret. Compile-time secrets are (in a way) really only secret for you or other people with access to the build environment—in the actual binary, it’s all going to be there in the clear. It’s quite common that you won’t be able to optically read back the secret values without resetting them.
In terms of pros and cons, it goes something like so:
✅ The simplest option
✅ The fastest option
✅ Free or essentially free
❌ Should only be used for statically known, mostly insensitive values
❌
Secret is coupled to the time of compilation; rotation requires rebuild and means
potential downtime
❌ Assume anything baked-in during compile time can
be exposed; this issue can be somewhat mitigated from attacks from the general
public if the system in question is a back-end or otherwise “private” system
Side note: Using the CI tool or an external tool for compile-time secrets
Then what about storing compile-time secrets in GitHub and/or an external system, like Hashicorp Vault or AWS Secrets Manager? Should you use one, both, neither?
The way I would recommend it is:
- Use your CI environment to host configuration values and mostly insensitive values as “secrets”. This minimizes your pain in accessing them. The CI environment tends to be shared and thus settings and so on can be seen by other teams, so assume people will have a possibility to see, if not the values, then how the code actually looks and retrieves values. You can typically have both shared/organizational secrets as well as repository-specific secrets, making it a flexible and simple option for the basic use cases.
- Using a separate tool like AWS Secrets Manager, especially when combined with things like workload-separated AWS accounts, can help you isolate secrets into a more gated environment where your team has greater access as well as the ability to actually read back the values. That’d result in you not needing yet another layer of password management—because, after all, where do you store the values that go into CI as you can’t retrieve them once they are in the system? With this approach you can opt for a shared keystore or decentralize it with teams/systems owning their own keystores.
In practical terms, I’d put all the basic baseline configuration into GitHub and I’d move anything I want to reuse—say, an important token that is shared between multiple repos within the same domain—into a keystore like Secrets Manager.
Run-time
Run-time secrets are dynamic and sensitive values that are required to be retrieved and used during the execution of the application. They are typically not known during compile time and need to be securely managed at runtime.
Common options include Hashicorp Vault, AWS Secrets Manager, Google Cloud Secret Manager and Azure Key Vault.
Using the AWS option, the below snippet would request the secret called “MySecret” during run-time.
import { SecretsManagerClient, GetSecretValueCommand } from "@aws-sdk/client-secrets-manager";
// Setup
const config = {
region: "eu-north-1",
secretName: "MySecret"
}
const client = new SecretsManagerClient({ region: config.region });
// Send command
const input = { SecretId: config.secretName };
const command = new GetSecretValueCommand(input);
const response = await client.send(command);
// Get value
const secretString = response.SecretString;
const secret = JSON.parse(secretString);
console.log('Retrieved secret:', secret);
With this approach, it’s imperative that the requesting party (say, the IAM role) has permissions to access the secret—but this rigor is also part of the magic of such solutions.
The logic around access to secrets is effectively pushed to the application. If you don’t need that in the application, this option won’t be right for you.
Pros and cons for run-time secrets:
✅ The most secure option and can be tuned to a much finer level of access
✅
The only reasonable option when you have more complex secrets setups (such as per
user)
✅ Decouples the secret from the runtime/application
✅ Ensures
correct (in time) validation and use of the secret
❌ Adds a bit of latency
❌ Adds cost
❌ Adds infrastructure/tooling
Diagram
I’ve provided the above questions as a, hopefully, helpful diagram. You can substitute the GitHub and AWS Secrets Manager icons to any equivalent product.
Note that the green boxes (using both icons) represent that either solution could be applicable.
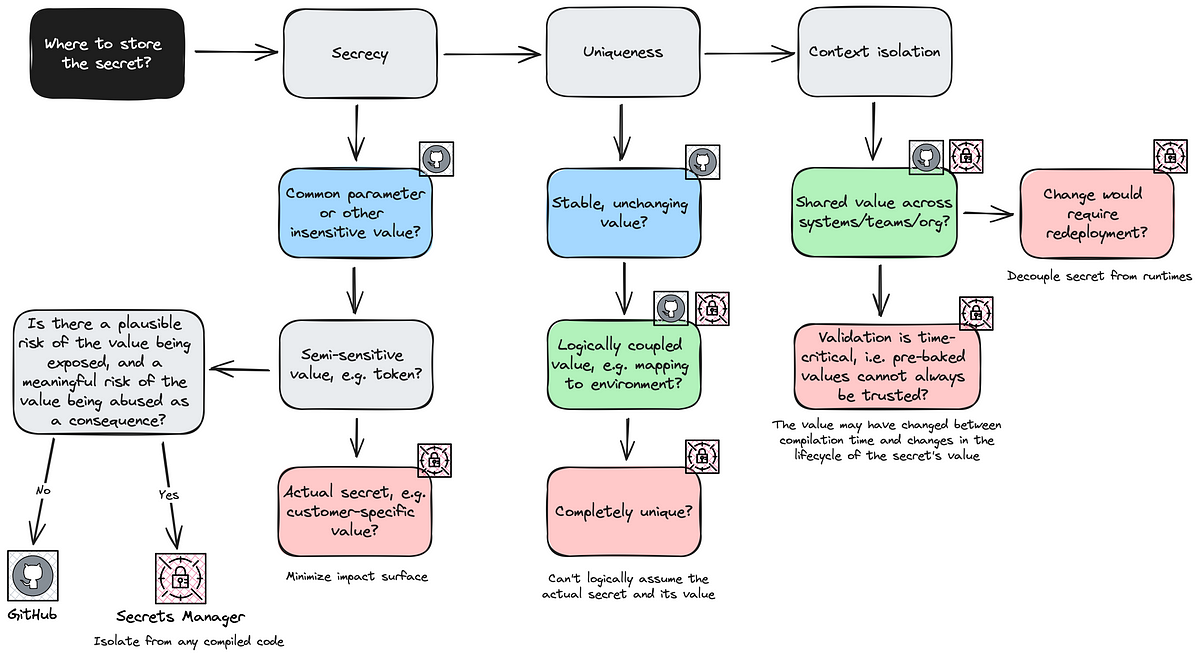
Given that these three questions are not individual tracks but depend on each other, you’ll have to weigh approaches once you at least clarified the rough parameters of your problem space.
Secrets management doesn’t have to be that hard and it gets a lot easier when you have a mental model to base your architecture on. Using this mental model should assist you in many of the common cases you’ll face in cloud-based software development.
Go and build some secure applications now, will ya? 🍻