
What is the cloud?
Part 1 of Cloud Developer Basics using Google Cloud Platform
It’s no longer enough to only think of development as either frontend or backend work — it’s all about having a wider, more rounded competency. Right now, the public cloud is the natural spot from which to grow one’s skills as it envelopes many of the ways-of-working and types of products you will want to be proficient in, when levelling up your know-how. This mini-course will take you through some of the most important concepts and services, always ending with you setting up actual micro projects.
This course is written as part of the internal skill development initiative at Humblebee, but we share it since there is a great demand for these skills. Want to work with a cloud-savvy company that naturally marries tech and design (as in UX, service, business and visual), or just plain old want to work here at Humblebee? Get in touch!
This mini-course is divided into six parts:
- What is the cloud? (This article!)
- Virtual machines and networking
- Containers and Kubernetes
- Serverless and APIs
- Storage and databases
- DevOps
Before we begin, a few words about me. I’m Mikael Vesavuori, a Google Cloud-certified Professional Cloud Architect—working at Humblebee—and I love what the public cloud can help us achieve, regardless of job title. I’ve worked with clients such as the Volvo companies, Hultafors Group, and most recently Polestar who are setting up a completely new architecture from the ground up.
Source code to follow along is available at https://github.com/mikaelvesavuori/cloud-developer-basics.
This mini-course is not sponsored by or connected to Google, other than us using their services.
Learning objectives and services covered
After following along in the theoretical and practical parts, you will have an introductory sense of the key functionalities of Google Cloud Platform, as well as some first-hand experience in running a tiny serverless application.
Services covered:
- Cloud Storage
- Cloud Functions
- Firebase Realtime Database
- IAM (Identity & Access Management)
- Stackdriver
Cloud evolution
What began as the contemporary public cloud less than 15 years ago, has continuously grown in capacity as well as capability, yet has become both easier to manage or work with, and offers more bang for the buck today than it did back then.
To quote Wikipedia, “Cloud computing is the on-demand availability of computer system resources”, which most easily translates into web sites or services being provided, with all their requisite network connectivity, storage (files, code, data) and processing power (i.e. render a web page).
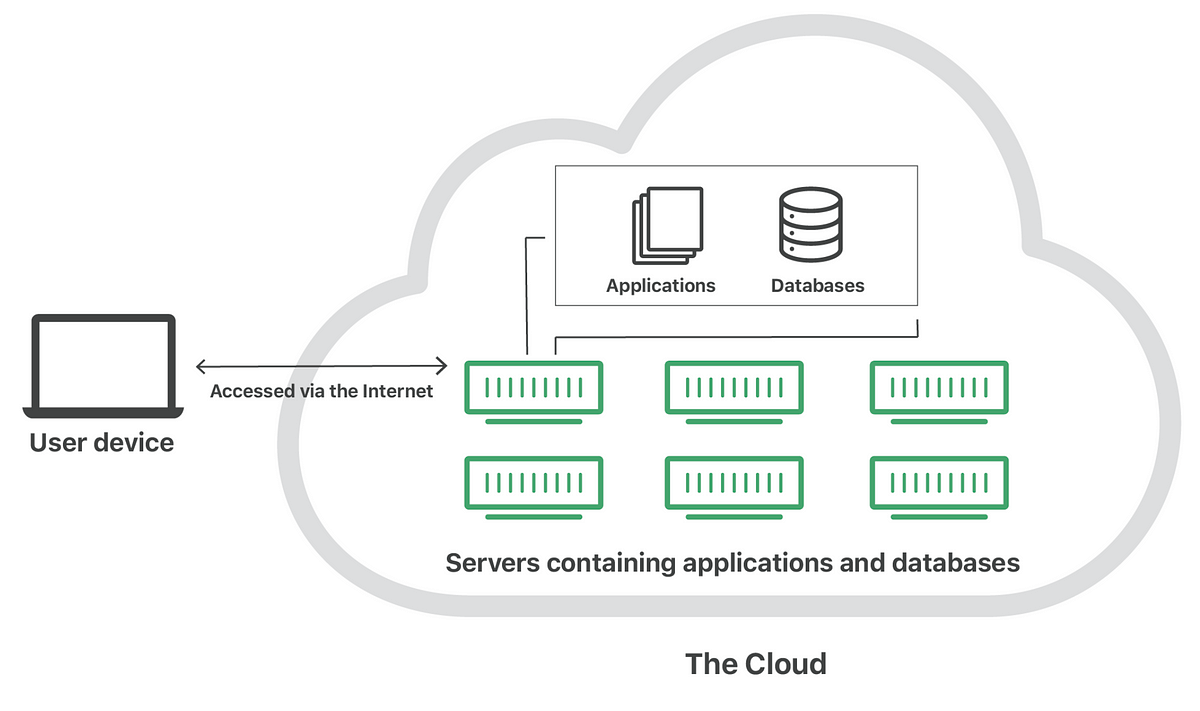
Over time, providers like Microsoft, Google, and Amazon Web Services have increased their managed offers. What is today called bare metal, meaning you basically just rent a regular computer, has evolved all the way to serverless, which requires no management or specialist competency to set up and run. The steps of abstraction, as listed by Microsoft, follow this outline:
- Infrastructure-as-a-service
- Platform-as-a-service
- Serverless
- Software-as-a-service

It’s important to understand that that “evolution” means less in terms of “later means better”, and more about operational concerns regarding the type of skills and investment you want to make and requirements you might have on operating and possibly owning the deeper layers. While a classic Infrastructure-as-a-service architecture might have its perfect cases still, the benefits of going serverless for example means that you can almost immediately put things in “production mode” across the world, but only by giving up a degree of control to gain that speed.
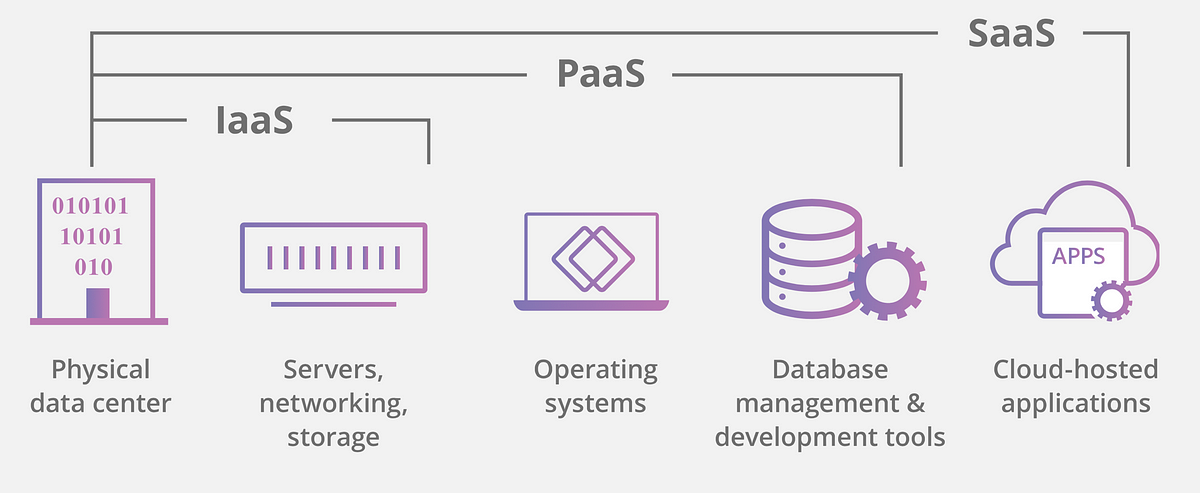
What is the Cloud?
While a cloud provider may have hundreds of services or offerings, they are usually really segmented into a small set of areas.
Compute
Computers gotta compute. Regardless if you need a firecracker or a planet-buster when it comes to capacity, there is a compute model and compute size for you.
Storage
Storage is getting more important as architectures are getting more stateless and your events have to reside somewhere. Exists as actual disks to in-memory caches.
Network
Traffic has to run back and forth into your applications. While much heavy lifting is done, lots of it is now virtualized and has to somehow be handled on your end as well.
Databases
Any variety of databases: zonal, global, relational or non-relational, serverful or serverless, document-oriented or whatever… There’s something for your use-case.
Provided apps & APIs
Ready-to-consume applications, services and APIs such as Cloud Vision.
Concepts
The following concepts will be briefly touched upon.
- Scalability
- Elasticity
- Durability
- Availability
- Regions and zones
- Virtualization
- Public/private/hybrid
- Operational expenditure
Scalability
The classic problem area that cloud can solve easily, which happens by scaling out (adding more resources) or scaling up (adding more powerful resources). This is traditionally done manually or by providing scaling thresholds. Scalability is important when we get more load or traffic.
Elasticity
Similar to scalability, but offers the factor of dynamically allocating resources without any additional manual labor. Having this managed reduces a great deal of manual overhead and greatly minimizes the need to preemptively expect high (or low) loads.
Durability
The measure of how resistent a record is against data loss and data corruption. Mostly used within the context of storage. Is often very high, such as 99.999999999% (11 9’s) meaning it’s highly unlikely that you will lose data.
Availability
Yet another classical area — how does one ensure that the application is always available? On top of this, the term high availability (HA) is added, meaning any practice that ensures that availability is always guaranteed, by means such as replicating data or applications over several regions.
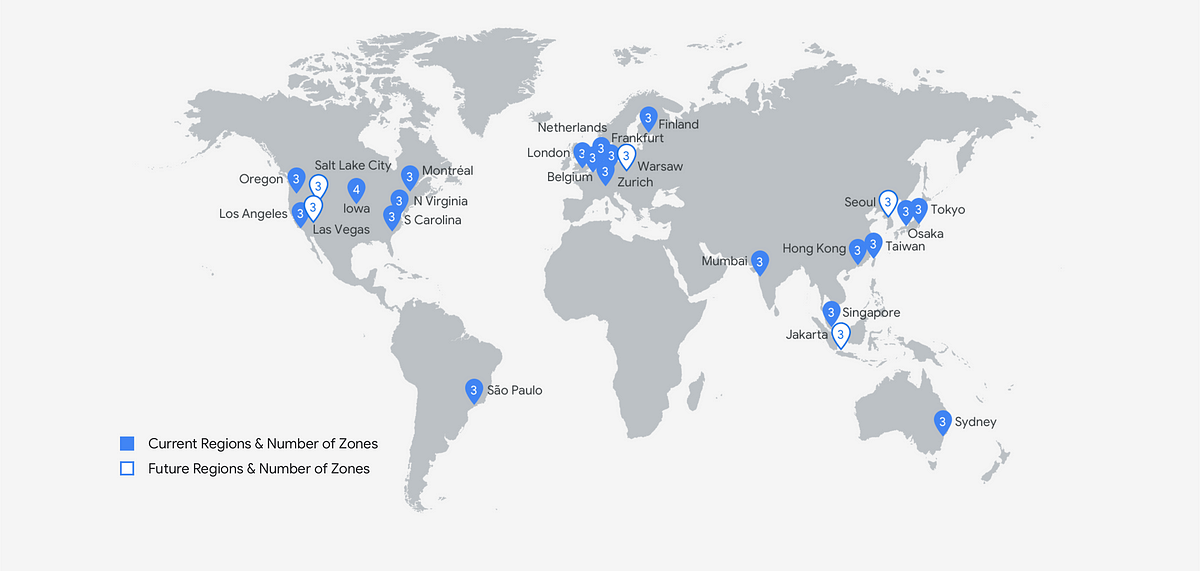
Regions and zones
Despite the heavy use of ”cloud”, it’s all really very physical. You still depend on actual data centers running hardware, with cables looping around the world. In GCP, regions are the bigger areas, all split into some number of zones. For high availability, you want to use more than one region.
Virtualization
Without virtualization there would be no cloud. Virtualization is the means of emulating hardware/software/storage with another tool, such as splitting a powerful computer into hundreds of smaller ones. This practice is most apparent within the context of compute.
Public/private/hybrid cloud
GCP, AWS and Azure are all public clouds, meaning you share resources from the vendor. A private cloud is something you own and run on your own. A hybrid is a mix of the two. Private clouds can for example be meaningful when you require very heavy security protocols.
Operational expenditure
Public clouds are promoting a financial model that is very dissimilar to traditional capital expenditure models. They profit from your increased usage rather than licensing fees. This means that a project has a markedly different economic character than ”pre-cloud”: it’s very cheap to start, but you need to be aware of your usage to benefit fully from this situation.
Workshop
In this rapid-fire workshop you will get a first taste of Google Cloud Platform, its interface and then go on to create a simple static-hosted website in a storage bucket, running a serverless backend function and saving user input into a serverless realtime database. You will also have set up a secure, least-privilege service account that handles your backend.
You should start with the code provided in the folder 01-what-is-the-cloud from the repository.
Step 1: Set up Google Cloud account (or log in)
If you are in an organization, you may need/want to do this through your Google Organization. Else, you sign up and get $300 of usage for free. If you already have an account, just sign in!
Optional: Install gcloud CLI tool
Consider installing the
gcloud
CLI tool if you want to work with GCP from your own computer.
Step 2: Get acquainted with the views and panels
Click around and pin some services to your left-hand side navigation panel. Use the top search bar to look for services and navigate faster. Try typing in functions, storage, api, and database.
Step 3: Try out the Cloud Shell
Open up a Cloud Shell instance. Try using it like your regular command line, drag-and-drop files into it, and test the code editor.
Step 4: Enable APIs
Go to APIs and services and enable APIs for services that are not already active:
- Firebase Management API
- Cloud Functions
- Cloud Storage
Step 5: Create a Firebase database
Google’s own description of Firebase is that it “is Google’s mobile platform that helps you quickly develop high-quality apps and grow your business”. It has a somewhat confusing brand since it overlaps many of Google Cloud’s own capabilities. For many typical applications, Firebase would probably fulfill all requirements without ever using Google Cloud itself. For our intents, we are only interested in the realtime database, which is Firebase’s marquee feature.
Go to the Firebase console and begin setting up your database.
- Click Add project
- Give it a suitable name, such as cloud-developer-basics-{YOUR_NAME}
- Don’t add analytics for now
- Under Get started by adding Firebase to your app, click the angle-brackets (Web) symbol
- Give your app a suitable nickname, such as cdb-{YOUR_NAME}; then register the app
- You will receive a code snippet — copy the contents of firebaseConfig into the pre-existing similar section in frontend/index.html
- Go to the Database tab and scroll down a bit, under Realtime Database click Create database — set it to test mode
Step 6: Create a Cloud Storage bucket
Navigate to Cloud Storage.
A storage bucket is used to contain files of any kind. This is the cloud-native way of handling files, even if there still exists traditional file stores as well, in most clouds. We will use one to contain our frontend assets and to serve it to visitors.
- Create a new bucket
- Give it a globally unique name and put it in a (single) region close to you, in our case europe-west1
- Set access to Set permissions uniformly at bucket-level
- Create the bucket with any other settings set to their defaults
- Don’t add any files yet!
Click the box next to the bucket and then click the three dots on the right-hand side. Select Edit bucket permissions. Click Add members. Type allUsers in the text field and select Storage Object Viewer for the role. Any files will now be publicly viewable as they become added, later.
Navigate into the bucket. Click the Overview tab and note down the Link URL. The gs:// address is the one you would need when pointing a CLI tool like gsutil, but it has no effect on the open web.
Step 7: Create a service account to securely run our backend
We are soon going to create a backend function. For security’s sake we will preemptively create a service account (a programmatic user) with only the rights to invoke (run) a function, but nothing else. This is a very good security practice so it makes sense to learn it already!
Go to IAM & admin, and into the panel Service accounts. Create a new service account, and give it a suitable rememberable name. For the role, give it Cloud Functions Invoker. This ensures it can only call functions, nothing else.
Later, when you want to use a service account programmatically, you will probably want to download the credential set in JSON format. This time, though, you don’t need it.
Step 8: Create a serverless backend with Cloud Functions
Navigate to Cloud Functions. Click Create function.
I have supplied several test functions that you can find in the folder /demo-cloud-functions. Try these out first! Get familiarized with the test panel as well. This will however not be the way you do deployments and function triggering in the future, but it’s a small handy tool for now. Later you will want to use something like Insomnia or Postman to try out your functions and APIs.
When you feel ready to deploy our getContent function (needed to continue with the next steps), go ahead and:
- Create a new function
- Set the timeout value to 10 seconds as you don’t want a serverless function to run for very long
- Ensure that Name and Function to execute are set to getContent, and that Region is set to europe-west1 under Advanced options (located in the far bottom)
- Choose Node.js 10
- For Service account, point to the account that you created in the last step
We want to co-locate the bucket and function so they may run at optimal speed. For more complex use cases, we can also negate any costs for ingoing or outgoing traffic by this kind of colocation.
Please note that the getContent function is set up to fetch content from DatoCMS. When you read this at some point in the future, this particular token and/or DatoCMS project may not be up. To replicate the same circumstances, then in DatoCMS you would:
- Create a model called article with a single-line string named peptext
- Add an instance of article with the text content “My name is {{NAME}} and I’m going to be a kickass Cloud Ninja!”.
If you completely want to skip the CMS, just return that text string from the function.
Copy-paste the code in backend/index.js into the view. Do the same for backend/package.json. Try running it with the following payload:
{
“name”: “SomeName Nameson”
}
Before you continue, make sure to note the function’s endpoint URL.
Step 9: Update index.html
In index.html, update the endpoint path (const ENDPOINT) and the image URL (background: url({URL_PATH})) to your own values. The image URL will be an absolute path, looking something like https://storage.googleapis.com/{PROJECT_ID}/humblebee.jpg.
Step 10: Upload frontend files into bucket and visit the page
Go to Cloud Storage and navigate into your bucket.
Drag-and-drop frontend/index.html and frontend/humblebee.jpg into the bucket. There should now be a symbol and text indicating that the files are public. Click the “link” symbol. The page should now display together with the background image.
Step 11: View logs
Navigate to Stackdriver logging. Filter for the function called getContent using the pop-out panels. Witness the glory of having a centralized nice-looking surface that gives you a peek under the almighty cloud hood.
Step 12: Revisit Firebase and validate that your visits are saved in the database
In Firebase, navigate to the Database tab. You should see that Firebase contains the name and timestamp of any sent input from the index.html site.
And with this, you are done! Give yourself a pat on the shoulder, you’ve deserved it.
Further studies
Listed here are recommended additional resources and tasks to improve your understanding and build up your foundational experience.
Explore more
- Use Firebase more, and attempt doing the classic CRUD actions (create, read, update, delete)
- Try writing more complex functions, by sending in parameters (available under request.body)
- Connect services like Cloud Vision to your Cloud Functions
- You may want to bookmark this free Coursera course if you are looking to get the ACE certification
References
- Google Cloud Platform Overview
- Getting Started with Google Cloud Platform
- An Introduction to GCP for Students
- Cloud computing terms
- What is cloud computing? A beginner’s guide
- HTTP Functions
- What Is the Cloud? | Cloud Definition
- Structure Your Database
- Qwiklabs Quest Preview — Baseline: Infrastructure
- Don’t get pwned: practicing the principle of least privilege
Qwiklabs
Qwiklabs are short and highly concrete lab-style tutorials. You need a free account to view them. To fully use these you need a paid membership — it should be possible to follow along and work your way through them on the free account though since the paid membership usually only adds the sandbox environment.