
Designing a Next-Level EventCatalog Setup for Event-Driven Architectures
EventCatalog is great! But you can make it even better—let me show you how.
David Boyne’s open source project EventCatalog is an “Open Source project that helps you document your events, services and domains”. It’s a great tool to create discoverability of your event landscape. I love it!
An open source tool powered by markdown to document your Event Driven Architecture.www.eventcatalog.dev
With it, you use Markdown to describe your events, services, and domains—it looks like this:
---
name: UserSignedUp
version: 0.0.1
summary: |
Tells us when the user has signed up
consumers:
- Email Platform
producers:
- User Service
---
Duis mollis quam enim, feugiat porta mi porta non. In lacus nulla, gravida nec sagittis vel, sagittis id
tellus. Vestibulum maximus velit eget massa pulvinar ornare. In vel libero nulla. Aliquam a leo risus.
Donec bibendum velit non nulla sollicitudin lacinia. Vestibulum imperdiet nunc eget
neque sagittis, eget volutpat purus ornare. Mauris malesuada finibus pretium.
Vestibulum suscipit tortor sit amet dolor tempor cursus. Nunc ac felis accumsan.
<Mermaid />
EventCatalog is then able to render that information—and its details, metadata, and relations—on a website that looks great and is easy to navigate. Many of us building event-driven systems have been clamoring for something like this for a long time.
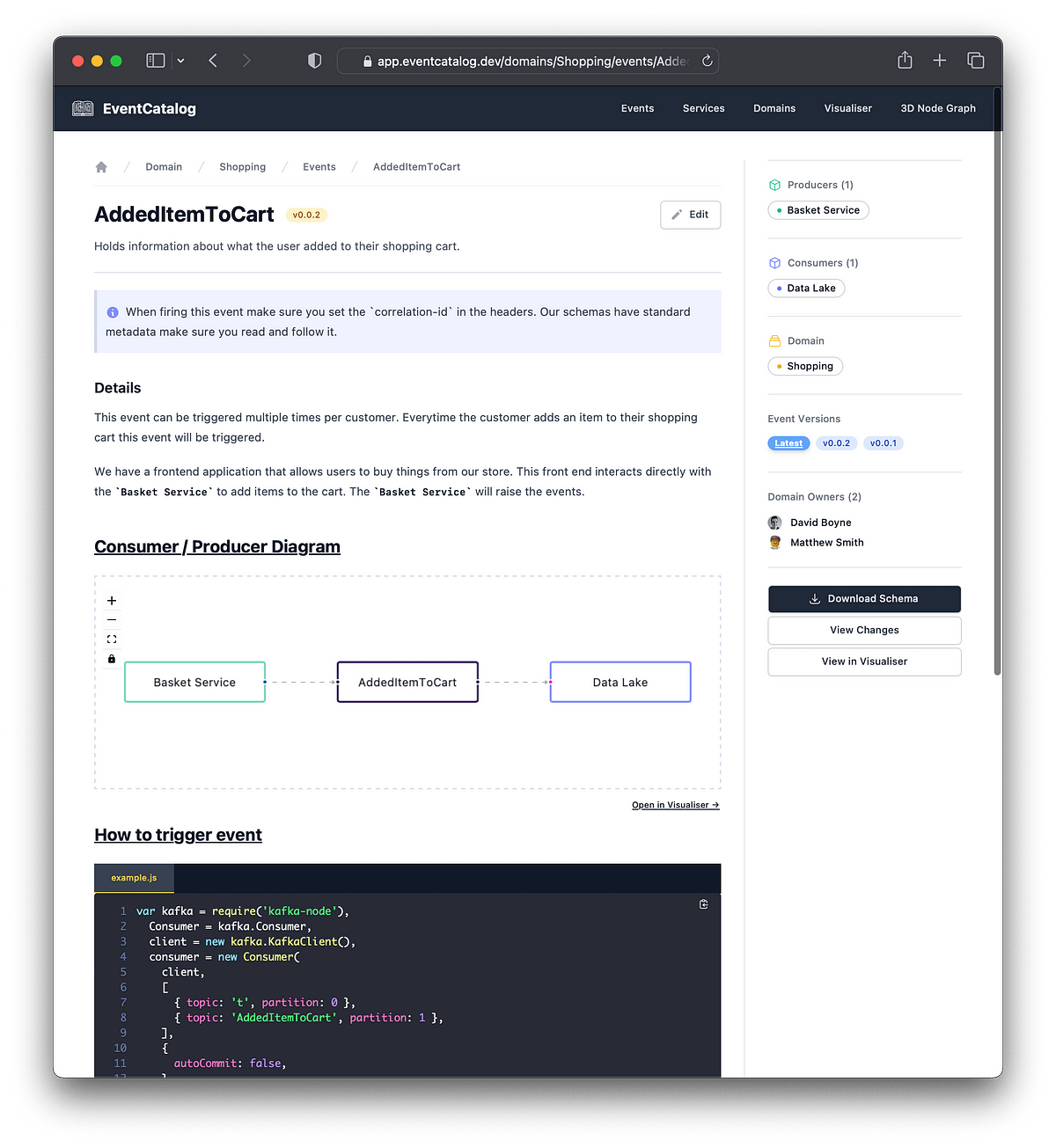
Since EventCatalog is pluggable and extensible we can start to plan for our automation needs, as you probably don’t want to build your event-driven systems in one place and document them somewhere else. Also, it’s not really ideal to “pull in” EventCatalog into your code base, given it’s a full project and not just a library. In short, we need to find some other way, and that’s one of the things I want to share with you here!
As good as EventCatalog is, there are things we need to add around it to tap its full potential.
What we want to improve on
Here’s what we want to do:
- Add support for AsyncAPI schemas and generating EventCatalog events (documents) from these, rather than writing them manually, external to the actual codebase we are documenting. The source of truth ends up being the documented systems, so EventCatalog can simply display that information.
- Fix a minor limitation of not getting the domain inferred from AsyncAPI schemas. The domain construct is a clever addition in EventCatalog, but there are no clear, standard ways of providing that information, so we’ll need to figure out how to do this.
- Design a solution for a centralized schema registry to separate it from any individual team, and to be able to use EventCatalog more like a platform.
- Provide a reproducible basis to scaffold our solution in a continuous integration environment.
Recently, I set up a small project that scaffolds the creation and build phases of EventCatalog and does most of the things above. For all of the above concerns, except the design part, I’ve shared that code in a public GitHub project:
Helps you automate the scaffolding of EventCatalog with AsyncAPI support and to generate events from such schemas…github.com
It won’t solve all the issues I am raising here, but it’s going to be a foundational part of how I approach the solution and the rest of the article. I‘ll explain some of why that code and solution works the way it does too.
Quick-start for the scaffolding solution
If you are anxious to just get a working demo solution, then my scaffolding project solves (more or less) 3 out of 4 issues here.
Clone the repository
Assuming you have
git, run
git clone [email protected]:mikaelvesavuori/eventcatalog-scaffold-asyncapi.git.
Create a new EventCatalog
Run bash create-eventcatalog.sh.
Run the EventCatalog
Alias the build-eventcatalog.sh script to something like
npm start, and then run it.
It should now run:
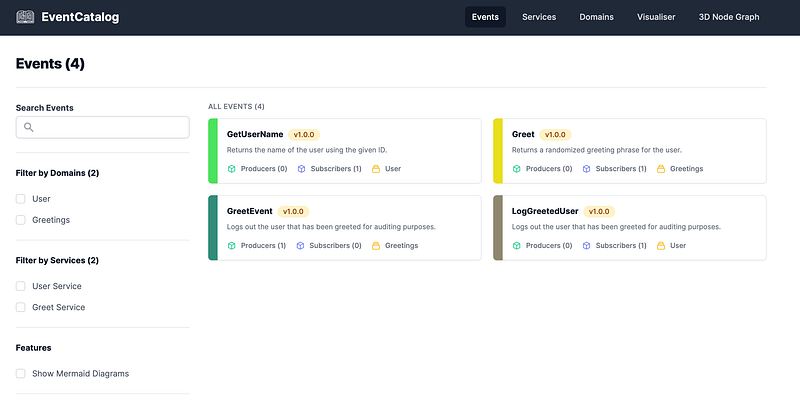
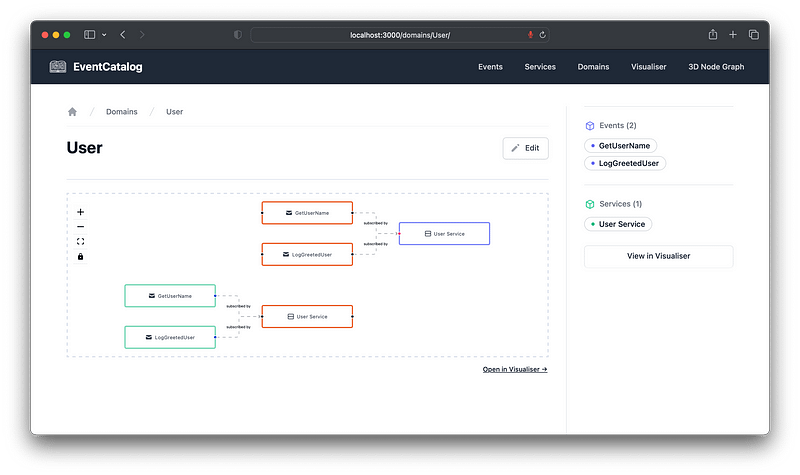
Even if you are using my project, the below will give you a much deeper understanding of how and why it works the way it does.
Let’s get started for real!
Adding support for AsyncAPI
AsyncAPI is becoming the de facto standard for describing hybrid and event-driven APIs. Given the nature of EventCatalog, supporting this spec makes a ton of sense.
Some example schemas are provided in my project so we can work with something concrete.
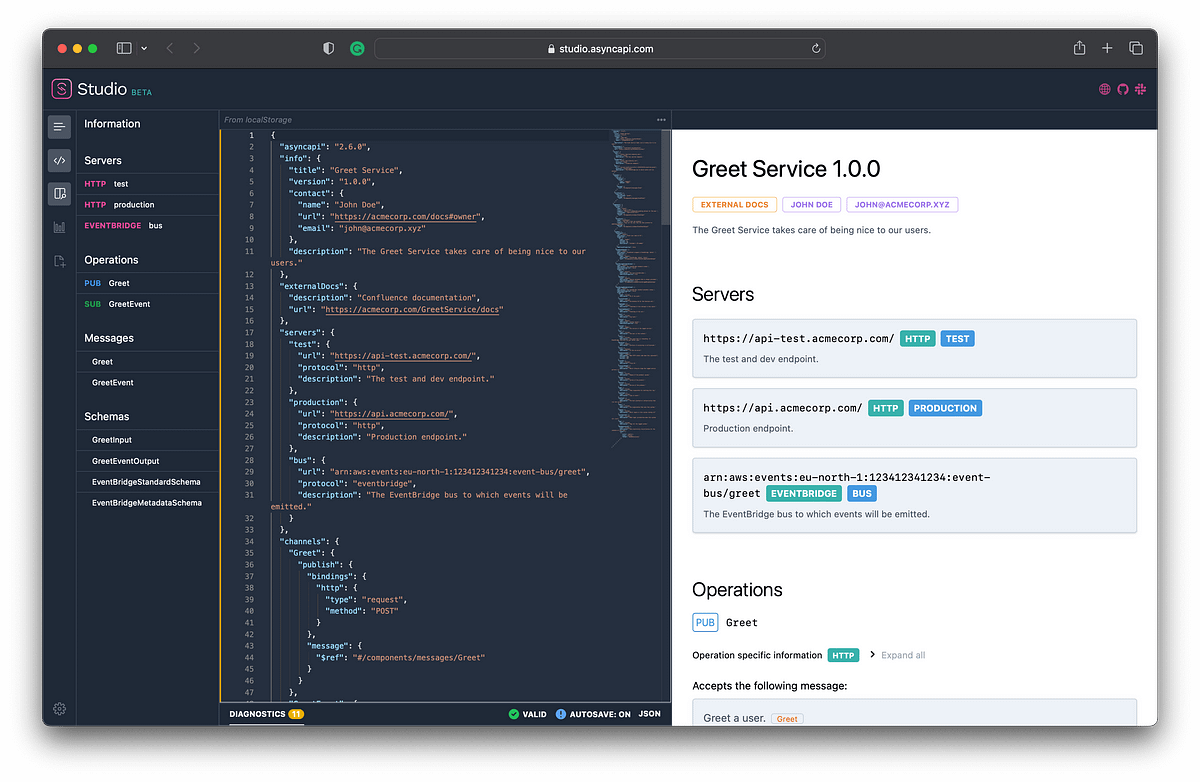
Supporting AsyncAPI is easy! There is already an AsyncAPI generator available, thankfully, so it’s not that hard to get something working in terms of outputting docs as expected by EventCatalog from your AsyncAPI schema files.
A basic configuration to add this support, based on the default config EventCatalog ships with, could be:
const eventCatalogConfig = {
title: 'EventCatalog',
tagline: 'Discover, Explore and Document your Event Driven Architectures',
organizationName: 'ACME Corp',
projectName: 'Event Catalog',
editUrl: 'https://www.acmecorp.xyz',
trailingSlash: true,
logo: {
alt: 'ACME Corp Logo',
src: 'logo.svg',
},
footerLinks: [
{ label: 'Events', href: '/events' },
{ label: 'Services', href: '/services' },
{ label: 'Domains', href: '/domains' },
{ label: 'Visualiser', href: '/visualiser' },
{ label: 'Node graph overview', href: '/overview' },
],
generators: [
'@eventcatalog/plugin-doc-generator-asyncapi',
{
versionEvents: true,
renderMermaidDiagram: false,
renderNodeGraph: true
}
]
}
module.exports = eventCatalogConfig;
As you see, the generators array refers to the generator and a bit of
additional config that will make this actually work. Feel free to fiddle with the
settings.
Now for the hard part. While this is “good on paper” it seems like there are unclear and bad issues with Next.js which runs EventCatalog when compiling the code.
That’s why I’ve had to create a bit of magic in my project that switches between a build-time and a run-time configuration. The way this works is a bit convoluted and has to do with certain limitations I’ve seen with Next.js and how it handles configurations. So, while ugly, the working solution is to adapt configurations for both use cases and simply swap them for each activity.
Inferring the domain automatically
In the
build configuration, you will find an elaboration on the above
solution, and also that we add a
domainName based on the structure of the file name.
return schemas.map((schemaName) => {
return [
// Use the AsyncAPI plugin to deal with this
'@eventcatalog/plugin-doc-generator-asyncapi',
// Config + produce the domain from the first part of the file name
{
...config,
domainName: schemaName.split('.')[0],
pathToSpec: path.join(__dirname, `${schemaFolder}/${schemaName}`),
},
]
});
But, why do it this way?
-
There is no domain concept in an AsyncAPI schema. While we can use custom
properties (specification extensions), prefixed with
x-, you’d need to make changes to the generator itself to read these back during the generation phase. Given that it’s non-standard behavior, it’s not even a relevant change to add to the generator project. -
You could certainly make a local copy of the changes and copy the file into the
node_modulesfolder and the local generator code, but that’s of course hacky and not reliable. For what it’s worth, I’ve done this for a bit, but it’s the worst possible solution. We didn’t become software engineers to settle for something like this. - Using the file name’s structure is the easiest one imaginable, as long as you can access some basic information about the file. While not an elegant solution (and it will only work if the files with the particular naming exist), it’s the one option that you can kind of control, at least for now.
- Later, we will look at and evolve toward a much better option.
The file name would therefore be something like
Greetings.Hospitality.GreetService.json which would refer to the scopes
of domain — system — service.
Note that JSON is not strictly needed, and you are free to modify the code for your own purposes. I would actually recommend using JSON, which the provided setup expects, as this format is typically more portable and is easier to validate and stringify than YAML files.
You should now have complete support for AsyncAPI schemas generating all required information, including what domain the system that the schema refers to is part of.
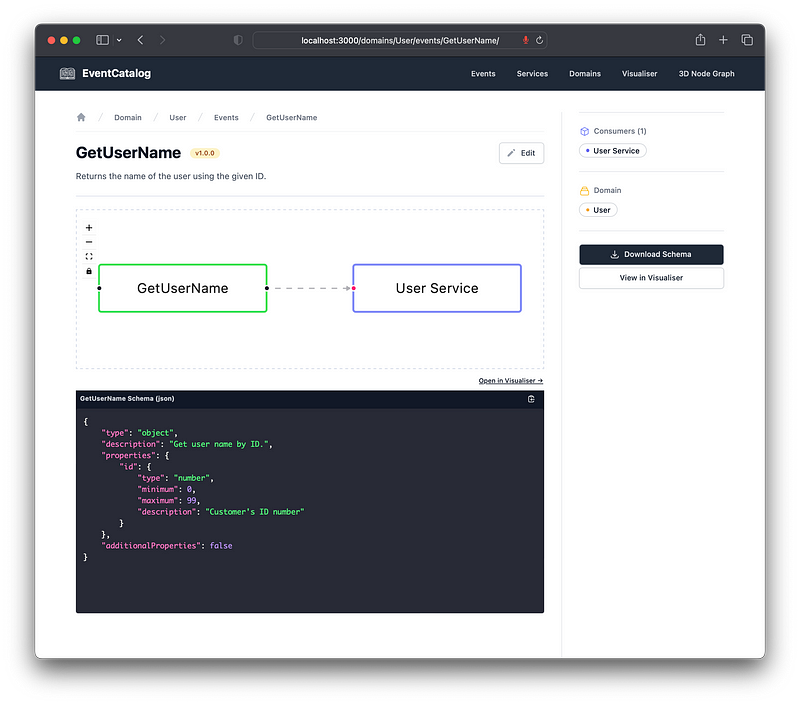
In the next section on design, we’ll see how we might be able to reiterate this later.
Designing a centralized schema registry
At this point, the additional functional support is in place.
We still need to figure out how to set things up if we want to use EventCatalog as a centralized resource. It’s really easy to get going with your local fork, stick in some schemas, start the dev server, be satisfied, built it, and deploy it somewhere. But, again, it becomes a bit more complicated if you have multiple teams who want to do this continuously, and where the source of truth resides outside of EventCatalog. Let’s try to solve this!
The overall context of the situation:
- We have some kind of CI/CD system (GitHub, GitLab, CodeBuild, Azure DevOps, Harness…) in which our systems will get tested, built, and deployed.
- We need to share our schemas from source services such as back-end services to a location where whatever is building EventCatalog can pick them up during build-time.
For the following, I will make some suggestions based on particular technologies. You should be able to port these concepts to similar products, but for the sake of showing something concrete I will point to AWS as our cloud provider for the back-end system (“the source system”), and Cloudflare Pages for the front-end part (i.e. EventCatalog).
Let’s walk through some ideas that might come up.
Idea 1: Pass the schemas from CI to blob storage
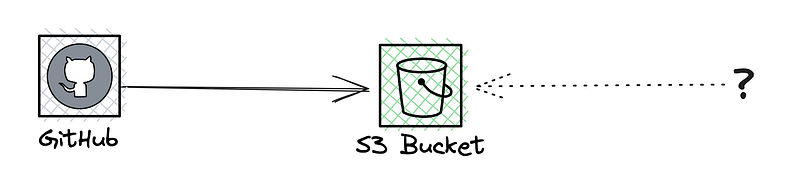
This will probably be something many will be reaching for. There is a sense of this being simple, safe, easy, and uncomplicated. However, the reality is that it’s none of these—I will address these shortly.
But mostly the big question is: If something is dropped into storage, how do we make sure the front-end’s build system knows this? We don’t yet have a complete solution, but we’ve identified the need for an external location for schemas.
Idea 2: Use S3 object events to write to a second persistence area
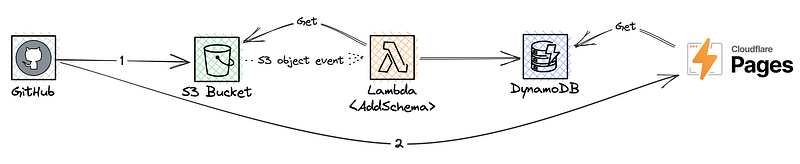
Since S3 can emit object events, we can run Lambda functions in response to files being added to the bucket. Admittedly this may not be possible in competing or similar services, but in AWS this is indeed possible. We could create the function, which gets the schema contents from the bucket (as the object event does not contain the contents of the object, just the name and some metadata) and writes the content to another persistence, such as DynamoDB, for access by other services.
Our CI’s job would have two distinct activities:
- Adding the schema to the bucket.
- Calling our front-end build system (such as Cloudflare Pages) to request it to start building.
While this solution is somewhat “complete”, at least compared to the first very vague concept, this whole thing is full of holes.
The first issue is that of security: GitHub would need to have credentials to write the file to the S3 bucket. Similarly, Pages would need to have credentials to call DynamoDB. Because these are not within AWS, we will have to use more painful or poorer (e.g. persistent credentials and long-living users) ways to make this happen.
Architecturally while this solution is doable in good (and less good) ways, this is also fundamentally a violation of service boundaries. Right now it’s just some pieces of free-floating infrastructure with willy-nilly access to external, non-AWS parties. This is not a good and clean service.
Depressingly, this particular solution also offers no clarity or insight into whether or not the input is correct. And while highly implausible in this specific case, given the partially asynchronous nature of the solution the second call (to CF Pages) DynamoDB could be in an inconsistent state when the front-end build starts, not using the most recent information. This is because the second call happens when the file is put in the bucket—it still needs to successfully run the Lambda to access, read, and add the contents to the table.
To make matters worse, if you don’t have clear error handling you might be making the second call even if the first call (adding the file) failed.
It’s messy as hell.
It would be much preferable to have a clearly defined service that contains the needed infrastructure and interfaces for both the producing and consuming parties.
Idea 3: Build an API

The absolutely most conventional and fitting solution here is to provide an AWS-contained API that can be called by the external CI system, such as POSTing a new schema that follows a well-defined shape, which can also be validated. We can then store it, and Cloudflare Pages can make a GET request and trivially retrieve all stored schemas.
This solution fixes many, but not all, of the previous issues. While not Supermax security, you could add an API key requirement here to provide a simple mechanism for ensuring unauthorized parties don’t use it.
Next, let’s bring this to the finish line.
Idea 4: Owning the full line of responsibilities
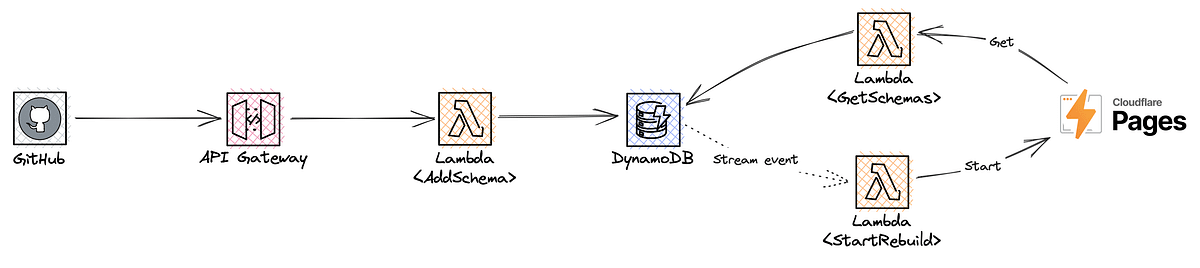
The above solution is good and fits our overall needs. But we can still make a vital improvement: We can remove the need for any knowledge, or leaky implementation, that is still required from the CI end. Why would they need to start the rebuild? Instead, we’ll use DynamoDB stream events which—on INSERT events—will start a Lambda that makes the call to the Cloudflare Pages API to do just that. This is also neither messy nor very hard to implement.
Best of all, the CI end only knows about one thing: That it has to call the schema API to pass the most recent schema. The service takes care of the rest.
For an elaboration on stream events, you might be interested in my AWS outbox demonstration project.
You’ll of course have to provide the schema registry/storage in this case, but you’ll be in a good position to automate the bulk of such a process using this project.
A service like this should for example:
- Require an API key, which is one of the few reasonable authorization options available under these circumstances.
- Take in an object that contains the schema itself, and also the service name, and its domain. This way we don’t have to store files in a specific format, but can instead get direct, truthful knowledge of where the schema belongs.
- Validate the input and ensure the schema is valid JSON.
-
Store the data, for example using a pattern such as
PKmapped to a broad concept, likeSCHEMA, andSKmapped to the service name. This way we can retrieve all schemas by making a query for the “broad” PK term—perfect for our front-end build process. - Data should be simple, stringified JSON; we’ve already validated that it’s valid JSON so no harm in doing it this way. Also, add an attribute for the domain name. Perhaps also add a timestamp attribute to understand the recency of the data.
The “StartRebuild” Lambda
This one is really easy. It just needs to call the Cloudflare Pages API and request the pipeline to run. With curl, this looks like:
curl --request POST \
--url "https://api.cloudflare.com/client/v4/accounts/$CLOUDFLARE_ACCOUNT_ID/pages/projects/$CLOUDFLARE_CATALOG_NAME/deployments" \
--header "Authorization: Bearer $CLOUDFLARE_AUTH_TOKEN" \
--header "Content-Type: application/json"
Adapt as needed to your language.
Making it work in CI
To package this for CI, we want to have a way of scaffolding this structure in a deterministic, reliable way every time there is (for example) a new commit to a code repository. EventCatalog itself already does quite a few things when “installing” it, so scripting this is not a biggie.
Once again, the
scaffolding project
offers this as it combines the two configurations (build-time and run-time) with the
installation, prepping, and moving of files, and deletion of boilerplate we don’t
need. The bulk of setting up the actual project is contained within the
create-eventcatalog.sh
Bash script.
What you will need to deal with, is making a few modifications so you aren’t loading the example schemas. Instead, pull the schemas from your registry. Other than that, it should be pretty much ready to go. Adapt it is needed to your circumstances.
The script will ask for a catalog (folder) name and use EventCatalog to generate it. For CI we can just give it a static name that is always used, since the CI environment is ephemeral. After installing, it will add the AsyncAPI generator and copy in the provided config files and example schemas. That should be most of what you need.
Lastly, I’ll outline the steps you’d need to implement in your CI pipelines.
Source system CI steps
- Install, compile, build, test, and do whatever you normally do.
- Push the schema to the registry.
EventCatalog CI steps
- Pull schemas from the registry.
- Build EventCatalog using the schemas as part of the configuration input.
- Deploy the site, such as with:
npx wrangler pages publish "$DOCS_FOLDER" --project-name="$CLOUDFLARE_PROJECT_NAME"
That’s it! You should now have everything in place! 🎉
In summary
I hope I’ve convinced you that it’s a worthwhile, and not too hard, investment to add some extra meat and bones around EventCatalog to make it seaworthy in larger organizations. No fault of the project itself, but at least this article hopefully gave you some practical directions on how to set it up as your event repository.
Good luck building and eventing!