
Which is Cheaper: Serverless or Servers?
Taking a simplified look at the costs of running workloads on common AWS compute services. TL;DR? “It depends”.
Whether you are still learning the basics of cloud computing, perhaps setting up your first serious pet project, or if you are deep into traditional IT operations, surely you have contemplated:
What is the cheaper option between classic infrastructure-as-a-service (IaaS) options like AWS EC2 and managed hybrid options like AWS Fargate or even fully serverless options like AWS Lambda?
In short: It’s complicated, and I’ll explain some of why that is, while we try to get some kind of answer to the question.
Please note that the products, services, prices and so on are AWS-specific but I would estimate that there are similar strategies and reasonings for Azure, Google and others as well.
I’ve prepared a Google Spreadsheet that you can copy. We will be using it throughout the article—feel free to make your own copy of it! You can certainly compare more than serverless versus servers with it if you want.
Basic recap of trade-offs
When it comes to the fundamentals of how the compute options differ from each other, I will relay it to others to discuss those particulars.
However, we can think of the critical trade-offs like this:
- EC2 offers predictable pricing and performance. Because it’s close to being bare metal, you can do most of the things you’d want from a computer, making it very flexible. However, there is a fair deal of management you need to do and you have to pay per minute or hour as it’s always on until you turn it off (or something bad happens!).
- Fargate offers the hands-off “serverless-ish” experience and runs on container images, so anything you can put in a container image is basically able to run on Fargate. You pay per request, on the whole, but you do need additional management and infrastructure for Fargate (not necessarily true for competing options in other clouds). Thus, Fargate offers high flexibility (but a little less than EC2) and keeps an overall serverless profile.
- Lambda ostensibly limits flexibility to runtimes that AWS supports (though these can be extended with both custom runtimes and container images). Lambda functions also cannot use ports and some other features, so if you are dependent on that, then Lambda will be too tightly constrained. The benefits are that these same contraints also enable a very rapid development flow (once you adjust) and they are truly fully managed — you need only apply other service-required infrastructure as needed and perhaps an API Gateway to front it to the internet. The functions only cost per invocation based on time running and their configuration.
That’s it, in a very tiny nutshell.
Why is it complicated?
There are several reasons why it’s complicated. I’ll share some of the things that come to my mind.
The first reason is the one I find to be the hardest:
How do we quantify an imaginary application and then infer its effects on specific hardware and configurations and, ultimately, the total cost?
The best that I believe we can do is to look at existing traffic patterns and use these as baseline data for our calculations. There is no such thing as a “generic” workload—it’s all contextual.
The second reason is that it’s a bit of an “apples to oranges” style comparison in the first place.
For example, in a serverless context, one of the major data points when calculating costs involves knowing the invocation count. For a server it might instead be utilization (average, median, max, minimum…) and the number of servers. These are all good and valid numbers, but they don’t measure the same thing:
- A server has the same cost whether it’s serving a single hit in a month or 10 million. This is not the case with Lambda.
- Conversely, there isn’t really a utilization concept in Lambda as it scales to zero when not in use and scales up practically all you want.
Therefore we need these different measures to meet in some comparable way.
Also, for obvious reasons, a solution with a server that needs additional infrastructure and management time is not strictly possible to compare with a solution that has none of those costs. Well, yes, in dollars, but we get additional concerns to consider, such as time invested in setup and maintenance, competency to run/maintain/develop the solution, and so forth.
So: We need to also look at things beside the “line item cost” in dollars. To be really picky, the title infers cost being the thing discussed, but bear with me.
As for the third reason, it has to do with the architectural qualities or “non-functional requirements” as they are traditionally called. Compute types (and services!) offer different sets of trade-offs as we noted at the start. For example, a strictly linear usage of resources is very different from highly variable traffic, bringing into question aspects like concurrency and scaling.
For more on those things, see:
Comparing how fast containers scale up in 2022 using different orchestrators on AWSwww.vladionescu.me
Then, a related point, is my fourth reason, which is the level of fit and applicability. Simply put, some types of applications or systems will have an inherently better fit for specific compute types. Given your requirements it may be literally impossible to run a specific workload on, say, Lambda (or EC2 or whatever!).
Calculating toward other models
These are some notes that might be helpful if you want to calculate from one compute model to another one.
EC2 to Lambda
This calculation should roughly be possible to do if you check your current monthly traffic (requests) and their average response time (compute time, not including latency). Given that Lambda is priced on precisely the compute time, request count and configuration, you should easily be able to size this right enough.
Also look at how your function scaling works for your workload.
Concurrency is the number of in-flight requests that your AWS Lambda function is handling at the same time. For each…docs.aws.amazon.com
Remember that EC2 systems are typically monoliths and may have several “paths”. In a Lambda landscape, you’ll probably want each “path” to be its own Lambda function. If this is the case, take this into consideration for scaling etc.
Lambda to EC2
I’m not really a “serverful” guy so I’ll do my best here to help a bit, at least.
The way I’d approach this is:
- Check your Lambda traffic patterns. Are they regular, predictable, or more chaotic? What’s the delta between low and high traffic?
- Pick a starting machine configuration that seems about right, based on your type of compute and traffic volume.
- Set up the machine with your system.
- Run a load test on the machine, using something like k6, to measure how many requests a second it performs.
- Based on your Lambda traffic patterns, you should be able to find the standard traffic, as well as seeing what the scaling needs are.
You can refer to the below if you want to have a basis for performance testing:
This is a basic starting point for conducting performance testing on AWS. - GitHub …github.com
And some resources for finding your right-sized instances:
What steps should I take to determine which Amazon Elastic Compute Cloud (Amazon EC2) instance is best for my workload?repost.aws
Ever wondered what EC2 configuration is the most optimal for your application? Have you ever tried different…www.concurrencylabs.com
Let’s compare!
Start by making a copy of the spreadsheet. The numbers were current as of November 26, 2023 (if I haven’t updated since then).
For exact calculations, visit the AWS pricing calculator:
AWS Pricing Calculator lets you explore AWS services, and create an estimate for the cost of your use cases on AWS.calculator.awscopy of the spreadsheet as much as you want, for example, by replacing the provided machine specifications with the ones you want to compare—use the Values sheet to add new data or update existing values. Once again: All of those can be fetched from the AWS pricing calculator.
Example calculations
Let’s put a monetary perspective on typical cases where each compute type is likely the best choice.
Lambda vs single EC2 micro instance: Stable low-to-medium traffic
The screen below is what you’ll see in the default setup of the spreadsheet. One of the things we can compare right away is Lambda (column B) vs a single EC2 micro instance (column D).
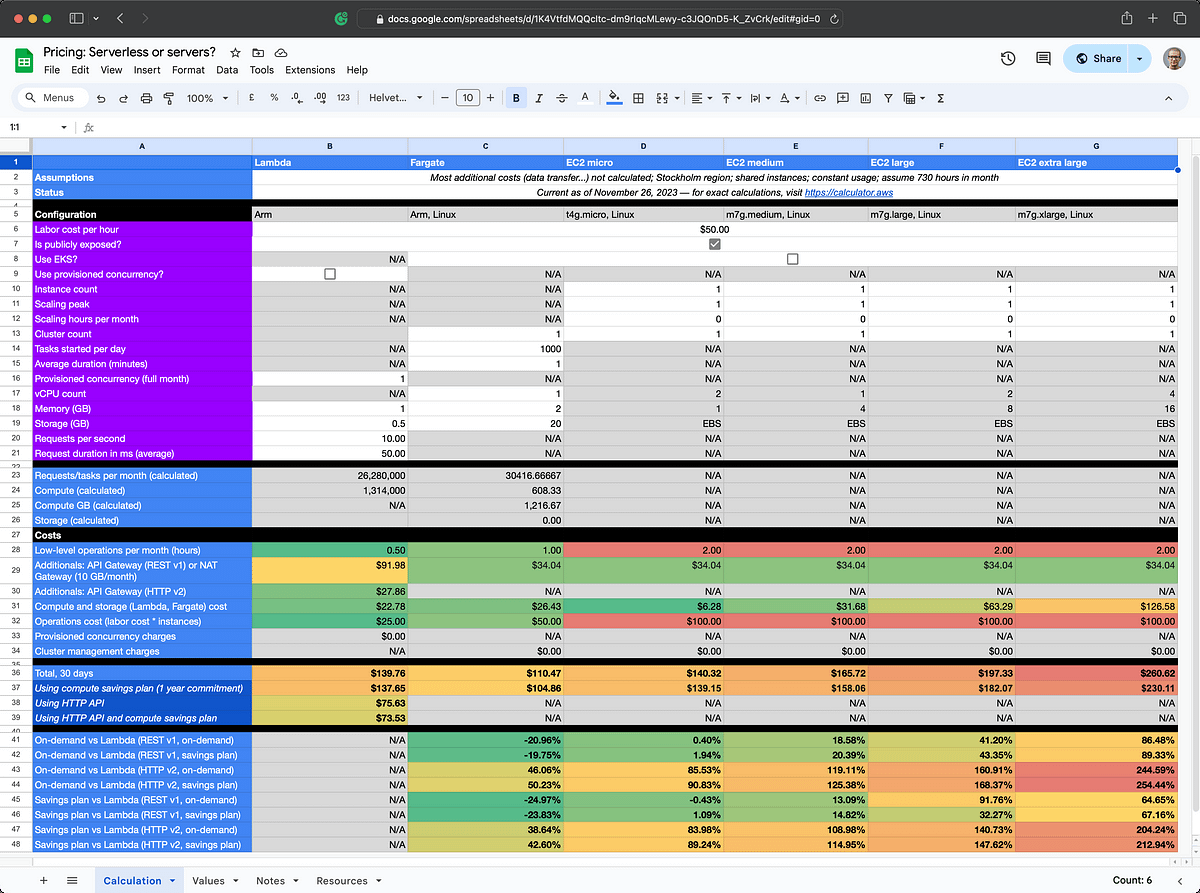
In terms of price, taking in a rough operations cost of 2 hours per month, they are roughly equivalent when comparing the micro instance to Lambda on API Gateway version 1. Using an on-demand HTTP API, the Lambda solution is ~38% cheaper.
However, in terms of all meaningful considerations around architectural qualities, such as high availability, the EC2 option should be immediately discarded. While we haven’t even started talking about performance, it bears mentioning that in my own testing the EC2 was indeed a bit faster but suffers from also being a much more primitive and unsafe solution.
We can use this as a start to disregard trivial conversations around Lambda vs EC2 for services that are below a certain threshold: In this case, roughly 26 million requests per month. Is that many or few? It depends, you tell me. For the contexts I work with, this is somewhere in-between, kind of medium. But we are still able to serve 26 million requests (10 RPS through a full month) with a lot of bells and whistles at the measly cost of ~$75 a month, if we want to.
Winner: Lambda.
Lambda vs Fargate: Long-running processing
Right out of the gate (…Fargate?) you’ll probably see Fargate as the winner. That’s what it should be good at, right? I’m definitely less into Fargate than Lambda, so let’s see if this example makes sense. Any way…
Here we’re looking at an example where there’s 1000 executions per day of a 15-minute processing workload. Lambda just happens to have a 15-minute maximum duration so having a workload that is this “precise” as an example is more theory than reality. We’d be close to hitting the wall all the time, so in a real scenario Lambda might have already fallen out of favor at this point, unless you can get around it some other way.
Anyway, let’s look at the numbers.
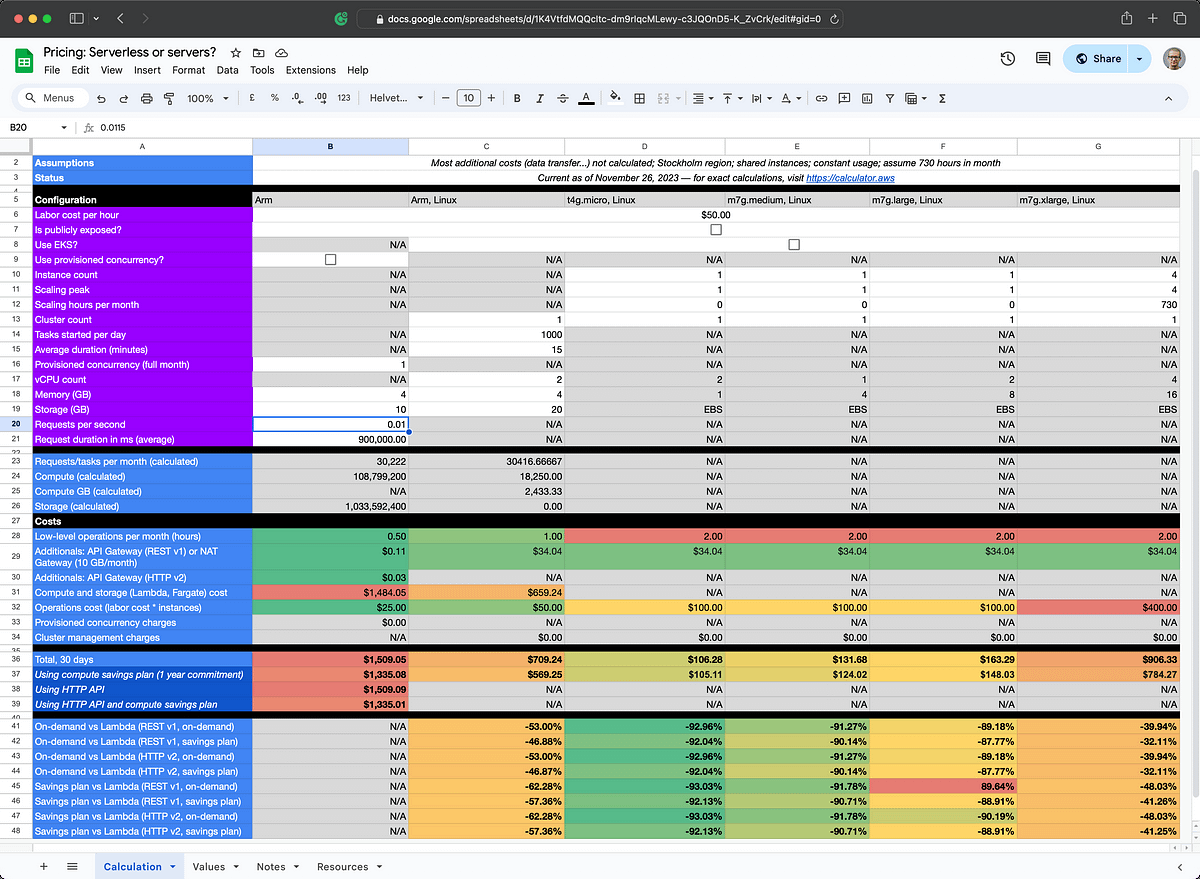
We don’t need publicly exposed services now, as it’s happening within our own environment. If Fargate is set to start 1000 tasks we’ll have a cost-performance ratio that is close to ~60% better.
Tasks are somewhat different than function invocations. So, about those tasks, ChatGPT 4 tells me that:
A “task started” event in Fargate means that a particular instance of your container has started executing. This could be due to scaling out (increasing the number of tasks due to load), a service update (replacing an old version of your container with a new one), or a fresh deployment.
Fargate tasks are generally long-lived compared to Lambda functions. They’re suitable for workloads that need to be continuously running or for tasks that might take a long time to complete.
Roughly, and theoretically, this would be the effect if the architecture assumes parallel (batch) processing. There may be a potential to rearchitect the solution and maybe crank down the tasks started number and save money? Maybe.
Anecdotally, if we’d compare to EC2, we’d probably want a fleet of cheap high-powered spot instances for something like this.
Winner: Fargate, to the best of my abilities in calculating this particular scenario.
Lambda vs highly available EC2: Dynamic high throughput workload
It’s hard to replicate dynamic conditions in the spreadsheet, unfortunately, but let’s assume a scenario in which we have requirements for very high throughput and lots of requests coming in. We need to scale up and down throughout the month.
In the below calculation, for Lambda (column B), we’ve turned on Provisioned Concurrency at 25 units, and updated to 1.5 GB of RAM. We are taking in an average of 100 RPS and duration is about 300 milliseconds each. All in all, a scenario where Lambda can do a lot of the heavy lifting for us, but the circumstances aren’t really ideal: A bit longish calls, a bit on the high side of memory, and so on.
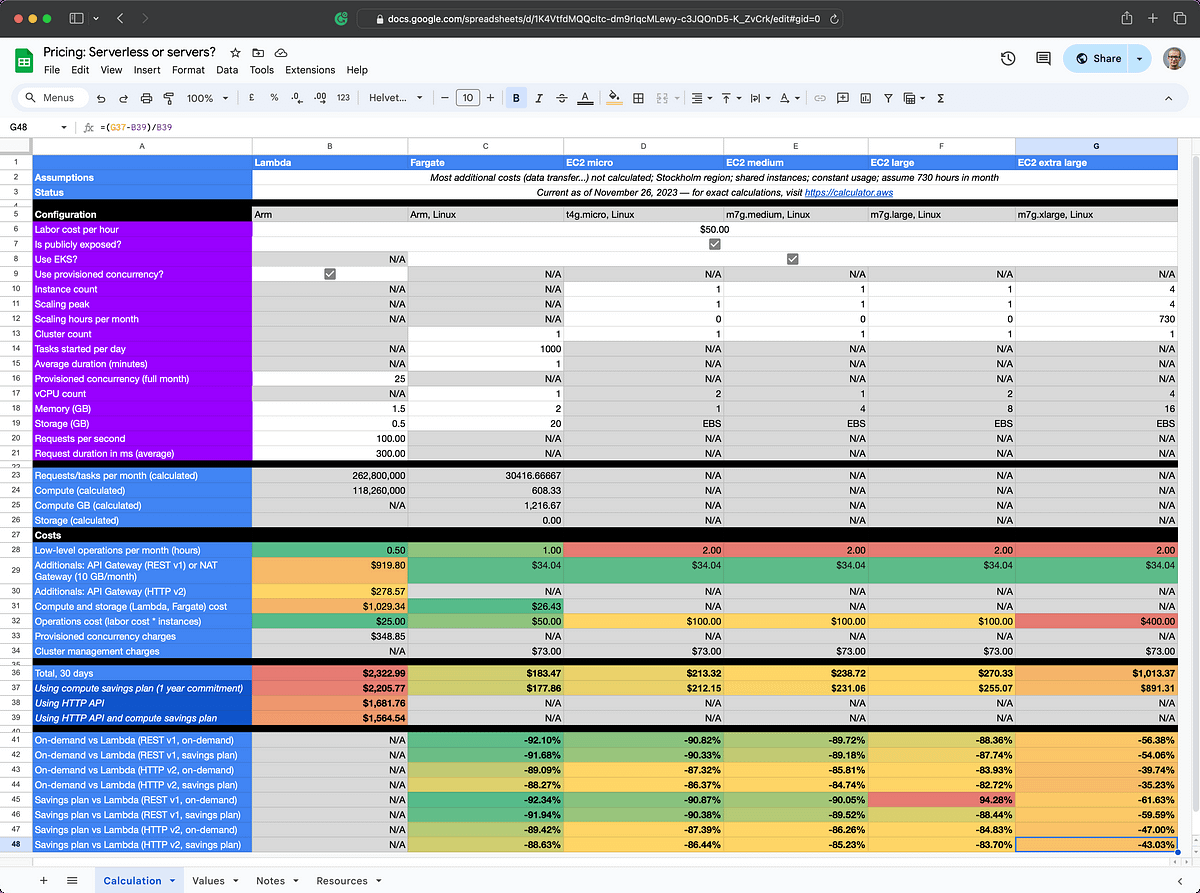
On the EC2 side (column G), we are getting a cluster of four m7g.xlarge machines and
setting them up in an EKS cluster. Even with this configuration, and assuming a fairly high operations
cost, this solution will be ~43% cheaper than the Lambda solution running at its most penny-pinching
setup, leveraging HTTP API and a compute savings plan.
Alas, it’s not a perfect comparison because we still lack the management benefits of Lambda and a proper API Gateway—the EC2’s are left on their own beyond the NAT Gateway. Regardless, there is a bit of spending room here.
This serves as a good example that for some use-cases, indeed, EC2 will be a cheaper option, if you can fit in the work around them.
Winner: EC2.
General takeaways
Using the Google spreadsheet it becomes trivial (or at least easier) to get an understanding at which level it may be worth considering different compute solutions.
In closing, some takeaways for you:
- For Lambda, Provisioned Concurrency can save you a lot of money—but only once you start having fairly high traffic volumes.
- For internet-exposed Lambda functions, the API Gateway costs will likely be far bigger than the function cost itself. HTTP APIs (or “V2 APIs”) greatly reduce cost for that sub-cost.
- As for Fargate, it’s really about the number of tasks started per day.
- Fargate can be a very price-conscious option when comparing with Lambda, but be aware that it’s (for better and worse) a more conventional option and requires more additional infrastructure and maintenance than Lambda.
- For EC2, compute savings plans can help you save a fair bit of money for the trade-off that you’ll have a commitment for a year or more.
Endnote: Real-life cost-efficient serverless at Polestar
At Polestar, where I’ve worked for 5 years, we’ve had a serverless-first strategy since 2019. Of the more non-sexy, non-car success stories, this is one of the things I feel deserves telling more about. In Polestar’s landscape (as of 2024) the vast majority of custom software is running on serverless compute, specifically AWS Lambda.
So, how cheap can it be? Even if I wanted to give specific numbers it’s always the question of the relative factors. For example: Is 100 million requests per month a lot for you? A drop in the ocean? Is your landscape possible to run serverlessly? Is it already divided into clear responsibilities, or will the “microservicification” be painful for your organization? All of this matters. But we do have a number of services that cost no more than double digit dollars per month to run with bells and whistles that would cost many, many times more were it not for serverless.
Given the company has several hundreds of software engineers and tons of teams supporting a wide range of digital products, Polestar has ended up with what can be called a “wide and shallow” landscape. That is, many applications are mostly (or entirely) independent of each other. If systems were more monolithic, we could (at least theoretically) accumulate or clump traffic into fewer infrastructure resources and scale that “blob”—but of course, that makes a very strange argument for “big balls of mud”! 😅
From what we’ve learned in this article, this type of landscape—with frequent changes and mostly independent systems—mean that we can save lots of money by running systems in a serverless manner: Individually, each system runs (in relative terms) fairly contained amounts of traffic. Each system scales independently and is, on their own, usually very cheap to run. We’ve seen typical “serverless costs” (Lambda, DynamoDB, EventBridge…) being a fairly minor part of Polestar’s overall AWS costs.
With such clear and granular isolation, down to specific AWS accounts for each service and environment, it’s easy to get crisp insights into how teams are handling their serverless infrastructure. While serverless components like DynamoDB and Lambda may offer less configurability than classic alternatives, it’s important to know that these can (and should) still be checked every now and then as conditions change around your system. We’ve at several times found big—50% or more—improvements on running costs by making very simple adjustments like:
- Running Lambda with ARM architecture and updating runtimes to more recent versions;
- Using heuristics or a rel="noopener" target="_blank">AWS Lambda Power Tuning) to reduce the memory size of Lambda functions;
- Adding selective DynamoDB provisioning to tables, since we default to on-demand and “grow” into using provisioned tables when there is empirical data to support that transition.
When the overall cost is negligible, of course even 50% does not add up to “real” money, but indeed some systems where we have optimized have lead to improvements of thousands of dollars per month, with only little effort.
Another big improvement of serverless is the ease of enablement and developer acceleration. The Platform Services team catering to enabling teams and engineers to use AWS is also very small, yet effective, largely because they are also serverless-first. The industry standard for these kinds of teams is said to be about 19%—at Polestar it constitutes about ~0.2–0.3% of all staff or ~1% on the department level. This is not because they are unwanted, it’s that serverless makes for an outsize effect on efficiency and enablement.
If you are still not on serverless I can only encourage you to try designing, building, and running something on it. I am happy to share more if you need that final push.
Thanks for taking the time to read! Hope you learned something and, again, be my guest and use the spreadsheet to inform yourself of the best compute infrastructure choices for your cases!